
[Paper Review] Abd-net: Attentive but diverse person re-identification
Abd-net: Attentive but diverse person re-identification
Chen, Tianlong, et al. “Abd-net: Attentive but diverse person re-identification.” Proceedings of the IEEE International Conference on Computer Vision. 2019.
Abstract
-
person re-identification에 attention mechanisms을 적용시키는 것이 효과적이라는 것이 연구되어왔지만, 이런 방식으로 학습된 attentive features는 종종 부자연스럽거나 다양하지 못함
-
Re-ID를 위해 attention과 diversity에 상호보완적인 Attentive but Diverse Network(ABD-Net) 제안
-
re-ID에 효과적인 features(more representative, robust, discriminative)를 학습하기 위해, attention modules과 diversity regularizations를 통합
-
상호보완적인 attention modules 쌍(channel aggeregation, position awareness)을 도입
-
hidden activations과 weights의 diversity를 효과적으로 보장하기 위한 새로운 orthogonality constraint 도입
-
광범위한 ablation 연구로 attentive term과 diverse term이 성능향상에 도움이 된다는 사실을 증명
-
많이 사용되는 person Re-ID benchmarks에서 SOTA 성능 달성
Introduction
- person re-ID : 다양한 시간과 위치에서 각 identities를 연관시키는 task
동작 방식 : query image와 gallery set이 주어지면, person re-ID는 각 이미지를 하나의 feature embedding으로 나타내고, 이를 gallery set에 있는 이미지들의 feature embedding similarities를 기준으로 ranking을 매김
- person re-ID는 실제 통제되지 않은 환경에서 사용하기에는 아직 challenges가 존재
challenges 원인 : body misalignment, occlusions, background perturbance, view point changes, pose variations, noisy labels
- 다양한 challenges를 해결하기 위한 많은 연구들이 등장
body part 정보를 통합하는 것이 feature robustness를 향상시키는데 효과적임이 경험적으로 증명
- 사람의 구별적인 appearance(body parts)를 포착하는 features를 얻기 위해, person re-ID에 attention mechanism이 도입되면서 많은 성능향상을 이룸
- feature embeddings이 이미지들 사이의 유사도를 계산하기 위해 사용됨 (일반적으로, Euclidean distance로 계산)
기존 문제점 : attention 기반 모델들로 correlation property이 낮은 features은 자연스럽게 보장되지 힘듦 (feature correlations이 높아야 함)
attention mechanism은 전체 이미지보다는 compact subspace(foreground)에 더 집중하는 경항이 있음 (fig1.(2))

- person re-ID를 위한 feature embedding은 attentive하면서 동시에 diverse 해야 함
1) attentive feature : misalignment 바로잡기, background perturbance 제거, body appearances의 구별적인 local parts에 집중하는 것이 목표
2) diverse feature : correlation이 낮은 features를 잘 다루고, 더 잘 매칭하는 것이 목표
- Attentive but Diverse Network(ABD-Net) 제안
- Contributions
1) attention modules : Channel Attention Module(CAM), Position Attention Module(PAM)
CAM : channel 단위로 feature 정보를 융합시킴
PAM : body의 spatial awareness와 part positions을 포착하기 위해 feature 정보 융합
두가지 modules이 상호보완적으로 도움이 된다는 것을 발견함
2) spectral value difference orthogonality(SVDO) : 새로운 regularization term 도입
직접적으로 weight Gram matrix의 conditional 수를 제한시킴
activations과 weights 모두에 적용되며, 학습된 feature correlations을 감소시키는데 효과적임 ??
3) 광범위한 실험을 통해 ABD-Net의 성능을 증명함
Attentive but Diverse Network
Attention : channel-wise and position-wise
-
re-ID를 위한 attention의 목적은 사람과 관련이 없는 backgrounds를 제거하면서 사람과 관련된 features에 집중하는 것
-
segmentation에서 아이디어를 얻어 2개의 상호보완적인 attention mechanisms을 통합시킴
Channel attention module
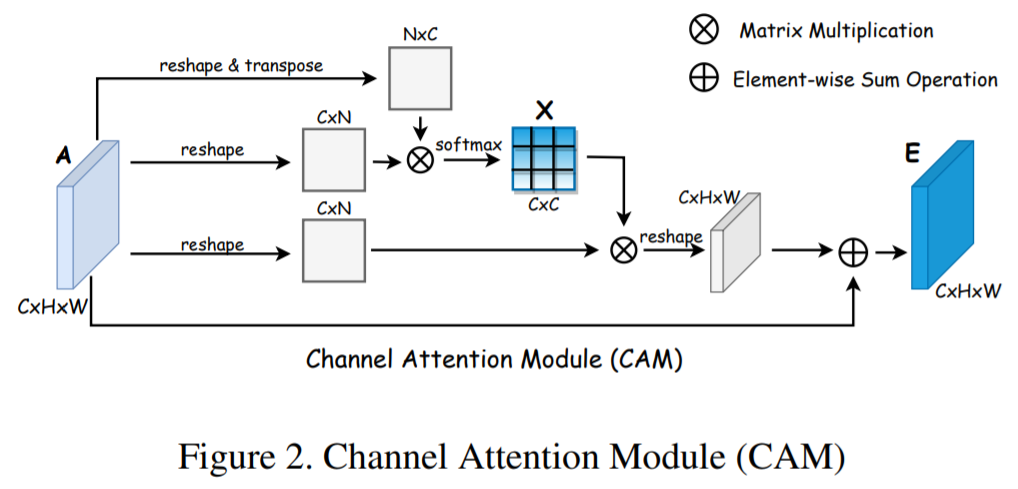
-
person re-ID에서 high-level channels은 그룹화 되어있고(몇몇 채널들이 비슷한 semantic contexts를 공유), 서로 더 연관이 있다고 가정함
-
CAM은 의미론적으로 비슷한 채널들을 그룹화하고 융합시키기 위해 디자인됨
-
input feature maps이 주어지면, 채널 affinity matrix를 계산
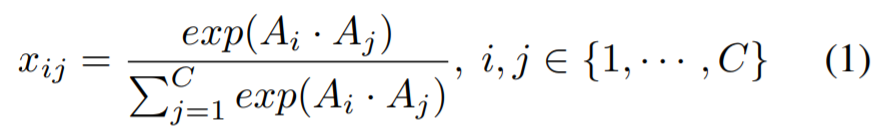
x_ij : channel i가 channel j에 미치는 영향
- 최종 output feature map E
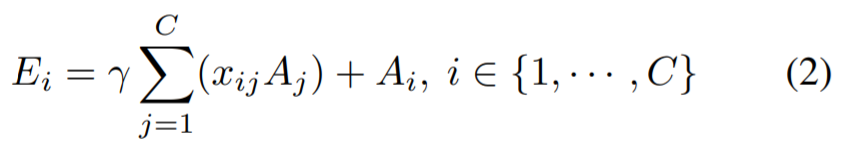
Position attention module
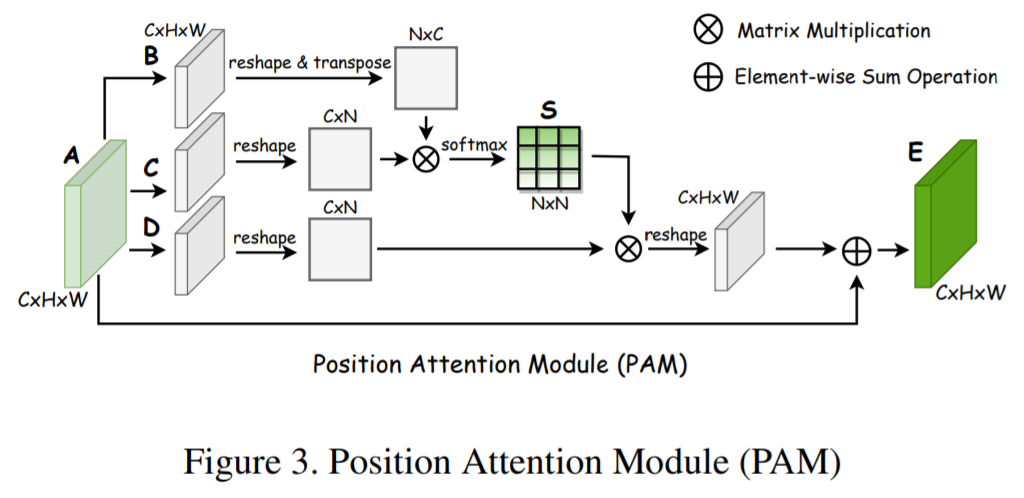
- PAM은 의미론적으로 관련된 픽셀들을 spatial domatin에서 포착하고 융합시키기 위해 디자인됨
1) input feature maps A가 BN과 ReLU activation을 취하는 convolution layers로 들어가 feature maps B,C,D 생성
2) pixel affinity matrix S를 계산
3) CAM과 비슷하게 output feature map E를 생성함
Diversity : orthogonality regularization
- orthogonality를 통해 diversity를 강화하기 위해, 새로운 orthogonality regularizer term 고안
hidden features와 weights 모두에 적용됨 (both convolutional and fully-connected layers)
-
Orthogonality regularizer on feature space(O.F.) : 직접적으로 매칭에 도움을 주는 feature correlations을 감소시킴
-
Orthogonal regularizer on weight(O.W.) : filter diversity 촉진하고, 학습 capacity를 향상시킴
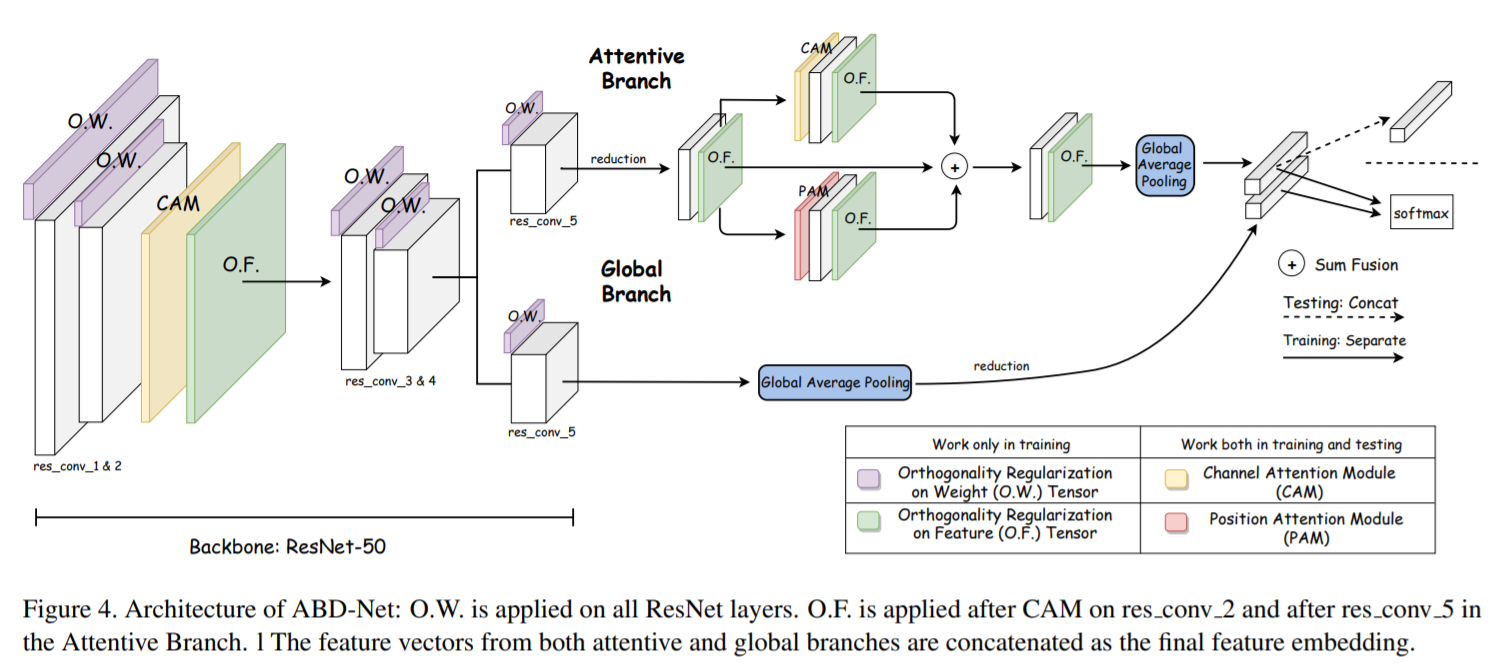
Network architecture overview
- backbone network : ResNet-50 (다른 네트워크도 사용가능)
1) res_conv_2 block의 outputs에 CAM과 O.F.을 추가
2) res_conv_3의 input으로 regularized feature map이 사용됨
3) res_conv_4 block 이후, 네트워크는 global branch와 attentive branch로 나누어짐
backbone network(ResNet-50)에서 모든 conv layers에 O.W. 적용
4) 2개의 branches의 outputs은 최종 feature embedding으로 concatenation 수행
- The attentive branch
1) res_conv_5 layer의 output이 reduction layer로 들어가고, O.F.이 적용되어 작은 feature map T 생성
2) feature map T가 CAM과 PAM에 동시에 들어감(with O.F.)
3) 두개의 attentive modules의 outputs과 feature map T의 concatenation 수행
4) global average pooling layer로 들어가서 k-dimension feature vector 생성
- The global branch
res_conv_5 layer의 output이 global average pooling layer와 reduction layer를 통과하여 k-dimension feature vector 생성
global context 정보 보존
- Loss function
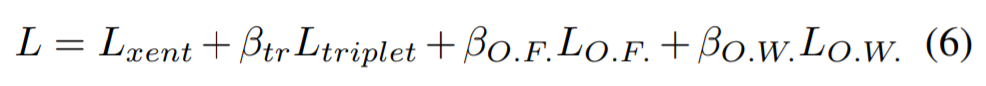
cross entropy loss, hard mining triplet loss, feature(O.F.)와 weights(O.W.)에 대한 orthogonal constraints penalty terms으로 구성
Leave a comment