
[Paper Review] Segnet: A deep convolutional encoder-decoder architecture for image segmentation
Segnet: A deep convolutional encoder-decoder architecture for image segmentation
Badrinarayanan, Vijay, Alex Kendall, and Roberto Cipolla. “Segnet: A deep convolutional encoder-decoder architecture for image segmentation.” IEEE transactions on pattern analysis and machine intelligence 39.12 (2017): 2481-2495.
Abstract
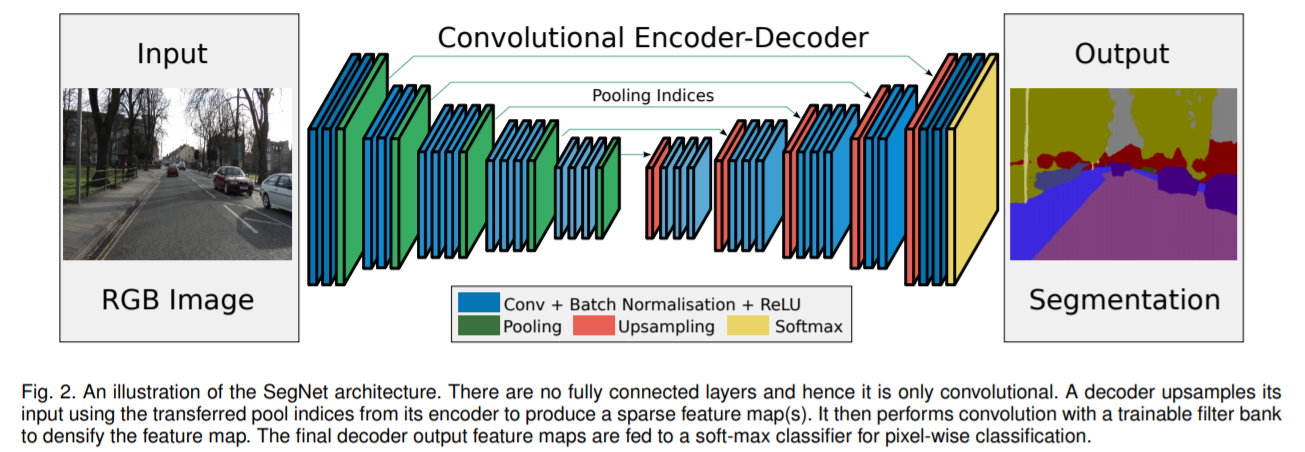
- 새롭고 실용적인 deep fully convolutional neural network 구조의 SegNet 제안 (semantic pixel-wise segmentation)
encoder-decoder 구조이며, 각 encoder에 해당하는 decoder가 있음
decoder의 마지막에는 픽셀 단위 classification을 위한 layer가 붙음(semantic segmentation 수행)
-
encoder network는 VGG network의 13개의 convolution layer와 동일 (FC layer 제거)
-
픽셀 단위 classification을 수행하기 위해, decoder network는 low-resolution encoder feature maps을 full input resolution feature maps으로 mapping
-
non-linear upsampling을 수행하기 위해, decoder는 해당 encoder의 max-pooling 단계에서 계산된 pooling indices 사용
upsampling을 학습할 필요가 없어짐 ??
-
upsampled maps은 sparse하고, 이를 dense feature maps으로 만들어주기 위해 학습할 수 있는 filters를 적용시킴
-
SegNet을 기존의 방식들(FCN, DeepLab-LargeFOV, DeconvNet)과 비교하면서, 메모리와 정확도 사이 trade-off를 밝혀냄
-
SegNet은 scene understanding applications에서 영감을 얻었기 때문에, inference time에 메모리와 계산 비용의 효율성을 고려하여 디자인됨
-
다른 구조에 비해 학습해야하는 파라미터들의 수가 상당히 적고, stochastic gradient descent를 사용하여 end-to-end 학습이 가능
-
road scenes, SUN RGB-D indoor scene segmentation task에 SegNet과 다른 구조들의 benchmark 수행

Introduction
-
SegNet은 픽셀 단위 semantic segmentation을 위한 효율적인 구조
-
road scene understanding applications을 위해 디자인되었고, 이를 위해서는 appearance(road,building)와 shape(cars,pedestrians) 정보를 모델링하고 서로 다른 클래스 사이 spatial-relationship을 이해할 수 있어야 함
도로와 빌딩과 같은 큰 classes 뿐만 아니라 작은 사이즈의 objects도 segmentation을 수행할 수 있어야 함
-
정확한 segmentation을 위해서는 추출된 이미지 representation에서 boundary 정보를 유지하는 것이 중요함
-
SegNet은 메모리와 계산 비용의 효율성을 고려하였고, 효율적인 weight update를 위해 end-to-end 학습(SGD 사용)이 가능하도록 디자인 됨
- The encoder network
VGG16와 convolution layer가 동일하며, FC layer는 제거함
- The decoder network
계층적으로 구성되어, 각 decoder에 해당하는 encoder가 있음
non-linear upsampling을 수행하기 위해, 해당 encoder의 max-pooling indices를 사용함
- unsupervised feature learning에서 영감을 얻어 디자인됨

- decoder에서 max-pooling의 값을 재사용하는 것의 장점
1) boundary delineation 향상
2) end-to-end 학습 시에 사용되는 파라미터의 수가 감소함
3) 해당 upsampling 구조는 약간의 수정으로 다른 encoder-decoder 구조도 적용 가능
-
최근 deep learning 기반 구조들이 segmentation을 위해 동일한 encoder 구조(VGG)를 사용하였지만, decoder의 구조는 다름
-
기존 방식들은 학습할 파라미터의 수가 상당히 많아서 end-to-end 학습이 어렵다는 단점이 존재
이를 보완하기 위한 많은 시도들 : multi-stage learning, pre-trained architecture 추가, inference시에 region proposals 지원, classification network와 segmentation network의 분리된 학습, 추가적인 데이터 사용(pre-training or full training)
- 추가적으로, 성능 향상을 위해 후처리 기술들이 필요
성능은 향상시키나 양적인 결과에서 좋은 성능을 달성하는데 필요한 핵심적인 디자인 요소를 분리하는 것이 어려움 ??
- 본 논문은 이런 방식들에 사용되는 decoding 과정을 분석하고 장단점을 찾아냄
-
본 논문은 SegNet의 성능을 2가지 task에서 평가 (Cam Vid road scene segmentation, SUN RGB-D indoor scene segmentation)
-
SegNet의 real-time online demo 제시(fig1)
Architecture
-
SegNet은 encoder network와 그에 해당하는 decoder network로 이루어져 있으며, 최종적인 픽셀 단위 classification layer가 있음
-
The encoder network : 13 convolutional layers(VGG16)로 구성, large datasets(ImageNet)으로 pre-training
high-resolution feature maps을 유지하기 위해 FC layer 제거하였고, 이는 encoder의 파라미터 수를 상당히 줄인다는 장점이 있음
- 각 픽셀에 대한 class 확률을 생성하기 위해, 최종적인 decoder output은 multi-class soft-max classifier로 들어감
The encoder
-
encoder network에서 각 encoder는 feature maps을 생성하기 위해 filter bank convolution 수행 (Conv+BN+ReLU)
-
2x2 max-pooling(S=2)을 수행하고, 이는 factor 2로 sub-sampling 됨
-
sub-sampling 전에 encoder feature maps에서 boundary 정보를 포착하고 저장하는 것은 매우 중요한 요소
하지만, encoder feature maps을 전부 저장하는 것은 실용적이지 못함
- 본 논문에서 정보를 저장하는 더 효율적인 방식을 제안
오직 max-pooling indices만 저장 (각 encoder feature map의 pooling window에서 maximum feature value의 위치만 저장)
The decoder
-
저장된 max-pooling indices를 사용하여 input feature map을 upsampling (sparse feature map 생성)
-
이후 feature maps은 학습할 수 있는 decoder filter bank를 통해 dense feature maps 생성
-
encoder 입력과 동일한 사이즈와 채널을 갖는 feature maps을 생성하는 기존의 decoder와는 다르게, 첫번째 encoder에 해당하는 decoder는 단일 multi-channel(RGB) feature map 생성
-
soft-max classifier의 output은 K channel image (K=class 개수)
가장 높은 확률을 갖는 class가 해당 픽셀의 class로 예측됨
Upsampling : SegNet vs FCN

Leave a comment