
[Paper Review] Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension
Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension
Lewis, Mike, et al. “Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension.” arXiv preprint arXiv:1910.13461 (2019).
Abstract
본 논문에서는 사전 학습된 시퀀스 투 시퀀스 모델인 denoising autoencoder BART 제안
-
BART 학습 과정
-
임의의 노이즈가 추가된 텍스트로 학습
-
모델이 원본 텍스트를 복원하는 법을 배울 수 있도록 함
-
일반적인 트랜스포머 기반 기계 번역 구조를 사용
BERT(양방향 인코더), GPT(left-to-right 디코더), 다양한 최신 사전 학습 기법으로 구성된 트랜스포머 기반 모델
논문에서는 가장 성능이 좋은 사전 학습 기법(noising approaches)을 찾기 위해 실험을 진행하였고, 기존 문장의 순서를 임의로 섞는 것과 새로운 in-filling 기법(text spans을 하나의 마스트 토큰으로 대체하는 것)을 사용하는 것이 가장 큰 성능 향상이 되는 것을 발견함
BART는 텍스트 생성 task로 파인튜닝할 때 특히 효과적이지만, 자연어 이해 tasks에서도 좋은 성능을 보임
BART는 GLUE와 SQuAD에서 RoBERTa의 성능을 따라잡았고, 다양한 tasks(abstractive dialouge, question answering, summarization)에서 새로운 SOTA를 달성함
또한, BART는 target 언어만으로 사전학습된 모델을 기계 번역을 위한 back-translation system에 적용하여 1.1 BLEU 향상시킴
-
Ablation 실험
BART에서 다른 사전학습 기법을 모사하여 end-task 성능에 얼마나 영향을 끼치는지 평가함
Introduction
Self-supervised methods는 다양한 NLP tasks에서 큰 성능 향상을 불러옴
가장 성공적인 접근법은 masked language models을 변형한 모델들이고, 이는 마스크된 토큰들을 원래의 토큰으로 복원하는 방식으로 학습되는 denoising autoencoders 임
최근 연구들은 마스킹된 토큰이 예측되는 순서, 마스킹된 토큰을 교체하는데 사용할 수 있는 context 등 마스크 토큰의 분포를 향상시켜 성능을 올리고 있음
하지만, 이러한 방식들은 일반적으로 특정 task(span prediction, generation)에만 초점을 두고 있기 때문에 다른 분야에서 활용하기에 한계가 있음
본 논문에서는 Bidirectional, Auto-Regressive Transformers를 결합시킨 사전 학습 모델인 BART 제안
BART는 sequence-to-sequence model로 이루어진 denoising autoencoder이고, 다양한 end tasks에 활용이 가능함
-
BART Pretraining
-
텍스트에 임의의 노이즈 추가
-
sequence-to-sequence model이 원본 텍스트를 복원하도록 학습
-
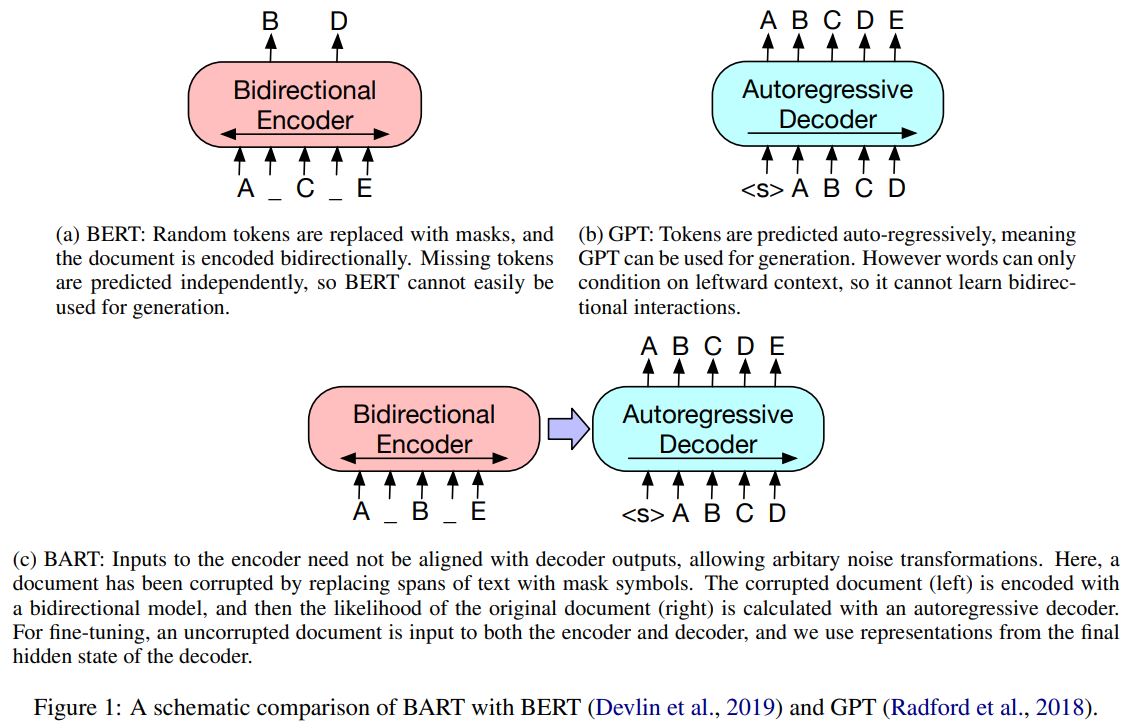
BART는 BERT(양방향 인코더), GPT(left-to-right 디코더), 다양한 사전 학습 기법들을 일반화한 트랜스포머 기반 기계번역 구조를 사용함
BART는 유연한 노이징 기법(길이 변형을 포함한 다양한 임의의 변형)을 통해 좋은 성능을 얻을 수 있었음
또한, 다양한 노이징 방법들을 평가하여 원본 문장의 순서를 임의로 섞는 것과 임의의 길이(길이가 0인 것도 가능)를 갖는 text span을 하나의 마스크 토큰으로 대체하는 것이 가장 좋다는 것을 발견함
이러한 접근법은 모델이 전체 문장 길이에 대한 많은 추론과 입력에 대한 긴 범위 변환이 가능하도록 하여 BERT의 사전 학습 tasks(masked LM, NSP)를 일반화할 수 있음
BART는 자연어 생성에 강하지만, 자연어 이해 tasks에서도 잘 동작함
GLUE와 SQuAD에서 RoBERTa의 성능을 따라잡았고, 다양한 tasks에서 새로운 SOTA 달성함
XSum과 비교하였을 때, 6 ROUGE 만큼 성능을 향상 시킴
BART는 몇개의 트랜스포머 레이어 위에 BART model을 쌓아서 기계 번역을 수행하는 새로운 fine-tuning 방법론 제시
이러한 트랜스포머 레이어들은 foreign 언어를 노이즈가 있는 영어 텍스트로 번역하도록 학습되고, 오직 target language(영어)로만 학습된 BART 모델을 그대로 활용할 수 있음
WMT Romaniam-English 벤치마크에서 강력한 back-translation MT baseline의 성능을 1.1 BLEU 향상시킴
-
Ablation Study
최근에 제안된 다양한 사전 학습 방식을 분석
분석을 통해 데이터와 최적화 파라미터를 포함하여 다양한 요소들을 신중하게 제어할 수 있도록 함
BART가 다양한 tasks에서 가장 일관적으로 좋은 성능을 보이는 것을 확인함
Model
노이즈로 오염된 문서를 원래의 문서로 복원하는 denoising autoencoder BART
오염된 텍스트를 입력으로 받는 양방향 인코더와 left-to-right autoregressive decoder로 구성된 시퀀스 투 시퀀스 모델
사전 학습을 위해, 원래의 문서에 대한 negative log likelihood를 최적화
Architecture
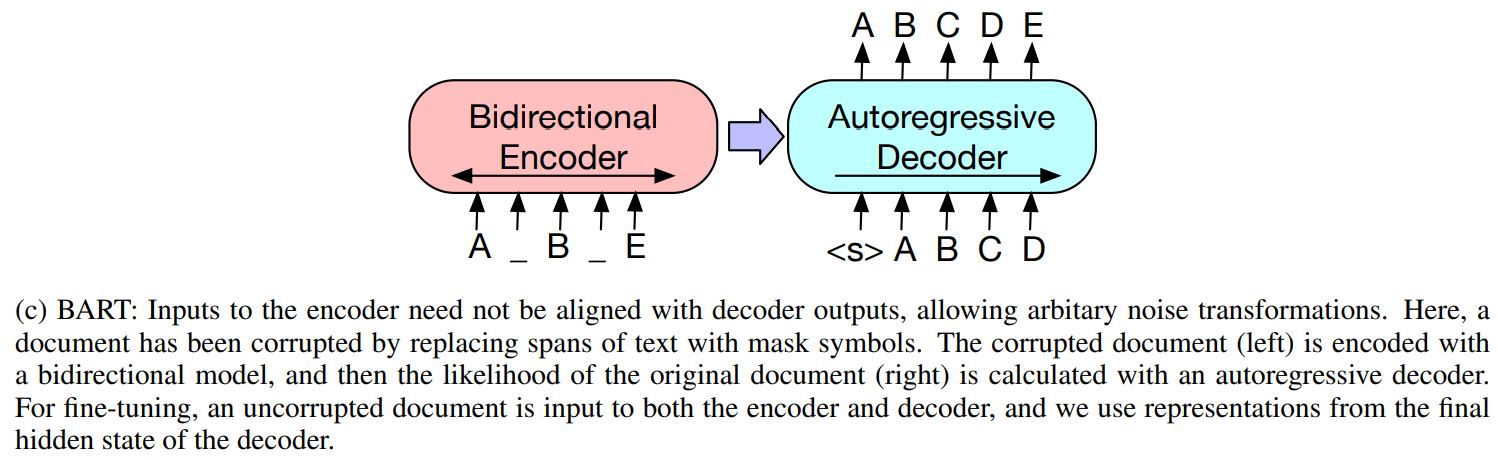
BART는 일반적인 시퀀스 투 시퀀스 트랜스포머 구조를 사용
트랜스포머와 다른 세팅 : GPT를 따라 ReLU 대신 GeLUs를 사용했고, 파라미터들을 초기화 함 $N(0,0.02)$
BART base : 인코더 6 layers, 디코더 6 layers
BART large : 인코더 12 layers, 디코더 12 layers
2가지 차이점을 제외하면 BERT와 구조적으로 매우 유사함
-
디코더의 각 layer에서 인코더의 마지막 hidden layer에 대해 cross-attention 수행
-
BERT는 단어 예측 전에 추가적인 feed-forward network를 사용하지만, BART는 사용하지 않음
또한, BART는 동일한 사이즈 BERT 모델 대비 약 10% 정도 많은 파라미터를 가짐
Pre-training BART
BART는 오염된 텍스트로 학습되고, 텍스트를 복원하는 방향으로 최적화됨
디코더의 출력값과 원본 텍스트 사이 cross-entropy 적용
특정 노이징 기법에 맞추어진 기존의 denoising autoencoders와 달리, BART는 모든 타입의 노이즈에도 적용가능함
극단적인 예시로 소스 문장의 모든 정보가 손실된 상황에서도 BART는 언어모델과 동일하게 동작
기존에 제안되거나 새로운 방식의 변형에 대해 실험을 진행하였고, 사전 학습 task에 따른 성능향상에 잠재력을 볼 수 있었음
BART에서 사용한 변형은 fig 2에서 확인할 수 있음
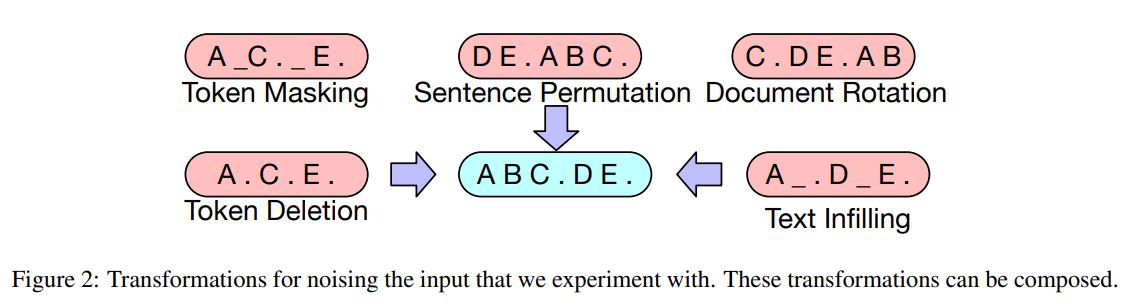
Token Masking
BERT를 따라 임의의 토큰을 [MASK] 토큰으로 대체
Token Deletion
입력 속 임의의 토큰들을 삭제하여 모델이 어떤 위치가 삭제되었는지 예측하도록 함
Text Infilling
푸아송 분포($\lambda$=3)에 따라 많은 텍스트 spans이 샘플링되고, 이를 단일 마스크 토큰 [MASK]로 대체
텍스트 span의 길이가 0인 경우도 [MASK] 토큰으로 대체될 수 있음
SpanBERT에서 영감을 얻었지만, SpanBERT는 clamped geometric 분포에서 span 길이를 샘플링하고, 각 span과 길이가 동일하게 [MASK] 토큰들을 붙여서 대체시킴
Text Infilling은 모델이 span에서 얼마나 많은 토큰들을 잃어버렸는지 예측하도록 함
Sentence Permutation
문서를 마침표 기준으로 문장으로 나누고, 이러한 문장을 임의의 순서로 섞음
Document Rotation
토큰이 무작위로 균일하게 선택되고, 문서가 해당 토큰으로 시작하도록 회전됨
모델이 문서의 시작을 찾아낼 수 있도록 학습시킴
Leave a comment