
[Paper Review] Language models are few-shot learners
Language models are few-shot learners
Brown, Tom, et al. “Language models are few-shot learners.” Advances in neural information processing systems 33 (2020): 1877-1901.
Abstract
최근 연구들은 대규모 텍스트를 이용하여 모델을 사전 학습시킨 후, 특정 task에 맞추어 fine-tuning 하는 방식으로 다양한 NLP task와 벤치마크에서 상당한 성능 향상을 이루었습니다.
하지만, 일반적으로 이러한 방식의 모델(task-agnostic)은 fine-tuning을 위해 task 별로 수천, 수만 개의 데이터가 필요하다는 단점이 있습니다.
이와 대조적으로 실제 사람은 단지 몇개의 샘플이나 설명만으로 새로운 언어 task를 수행할 수 있습니다.
논문에서는 언어 모델의 사이즈를 증가시키는 것이 task-agnostic, few-shot 성능을 크게 향상시키는 것을 확인하였고, 일부 task에서는 fine-tuning 방식의 SOTA의 성능과도 비교할만한 결과를 보여줬습니다.
구체적으로, GPT-3는 autoregressive language model로 1750억개의 파라미터를 가지고 있고, 이를 few-shot 환경에서 성능을 테스트하였습니다.
기존의 non-sparse language model의 10배 정도 크기
모든 task에서 GPT-3는 어떠한 파라미터 업데이트나 fine-tuning을 수행하지 않았고, 단지 텍스트를 이용한 상호작용만으로 모델이 task를 수행할 수 있도록 하였습니다.
GPT-3는 번역, 질의 응답, cloze task 등 다양한 NLP task에서 강력한 성능을 달성하였고, 이외에도 즉석 추론이나 도메인 적응이 필요한 task에서도 좋은 성능을 보였습니다.
또한, 논문에서는 GPT-3의 few-shot learning에서 잘동작하지 않는 일부 데이터셋과 대규모 웹 텍스트에 대한 학습 관련 문제에 직면한 일부 데이터셋을 확인하였습니다.
최종적으로, GPT-3가 사람이 판별하기 어려운 정도로 실제적인 뉴스 기사를 생성해낼 수 있는 것을 확인하였고, 이러한 발견과 GPT-3의 사회적 영향에 대해 논의하였습니다.
Introduction
최근 NLP 시스템은 사전 학습된 language representations을 이용하고 있고, downstream transfer를 위해 점점 유연하고 task에 구애받지 않는 방식(task-agnostic)으로 발전하고 있습니다.
-
단일 레이어로 학습된 단어 벡터 representations
-
여러 층의 레이어로 구성된 RNN으로 학습된 representations, contextual state
-
사전 학습된 recurrent or transformer language models
사전 학습된 모델을 특정 task에 적용하기 위해 fine-tuning 하는 방식으로 task를 위한 구조의 필요성을 제거하였습니다.
트랜스포머 기반 전이 학습 모델들이 상당한 성능 향상을 이루었지만, 여전히 task를 위한 데이터셋과 fine-tuning 과정이 필요하다는 단점이 있습니다.
특정 task에서 강력한 성능을 내기 위해서는 일반적으로 수천, 수십만개의 데이터를 이용하여 fine-tuning을 해야합니다.
이러한 과정이 필요하지 않다면 이상적일 것이라는 다양한 이유가 있습니다.
-
실용적인 관점에서 task를 위해 라벨링된 대규모 데이터셋의 필요성은 언어 모델의 적용성을 제한합니다.
너무 많은 종류의 task가 존재하고, 모든 task에 대해 대규모 데이터셋을 수집하는 것은 쉬운 일이 아닙니다.
-
학습 데이터에서 거짓된 상관 관계를 악용할 가능성은 기본적으로 모델의 표현력과 훈련 분포의 좁음과 함께 커집니다.
넓은 범위의 정보를 흡수하는 사전 학습 과정 후, 특정 task를 위한 좁은 범위로 미세 조정하는 것은 문제를 발생시킬 수 있습니다.
-
실제로 사람은 대부분의 언어 task를 학습하는데 많은 데이터를 필요로 하지 않습니다.
사람은 간략한 지시나 적은 예시만으로 언어 task를 수행할 수 있습니다.
이러한 적응성은 사람이 다양한 task와 skill을 섞거나 교차하여 수행할 수 있도록 합니다.
논문에서는 NLP 시스템을 넓은 범위에 활용할 수 있도록 이러한 유동성과 일반성을 갖기를 바랍니다.
이러한 문제를 해결하기 위한 방식에는 meta-learning이 있습니다.
meta-learning은 학습 시 모델이 넓은 범위의 기술과 패턴 인식력을 발달시킬 수 있도록 하고, 추론 시 학습한 능력을 원하는 task으로 빠르게 적용시키도록 합니다.
이는 실제 사람이 다양한 task와 능력을 섞거나 전환하며 자연스럽게 수행하는 방식과 유사합니다.
최근 연구들은 이를 in-context learning 방식으로 시도하였습니다.
task에 대한 자연어 설명이나 예시를 모델에게 주고, 모델이 다음에 나올 예시를 완성하는 방식으로 예측을 수행
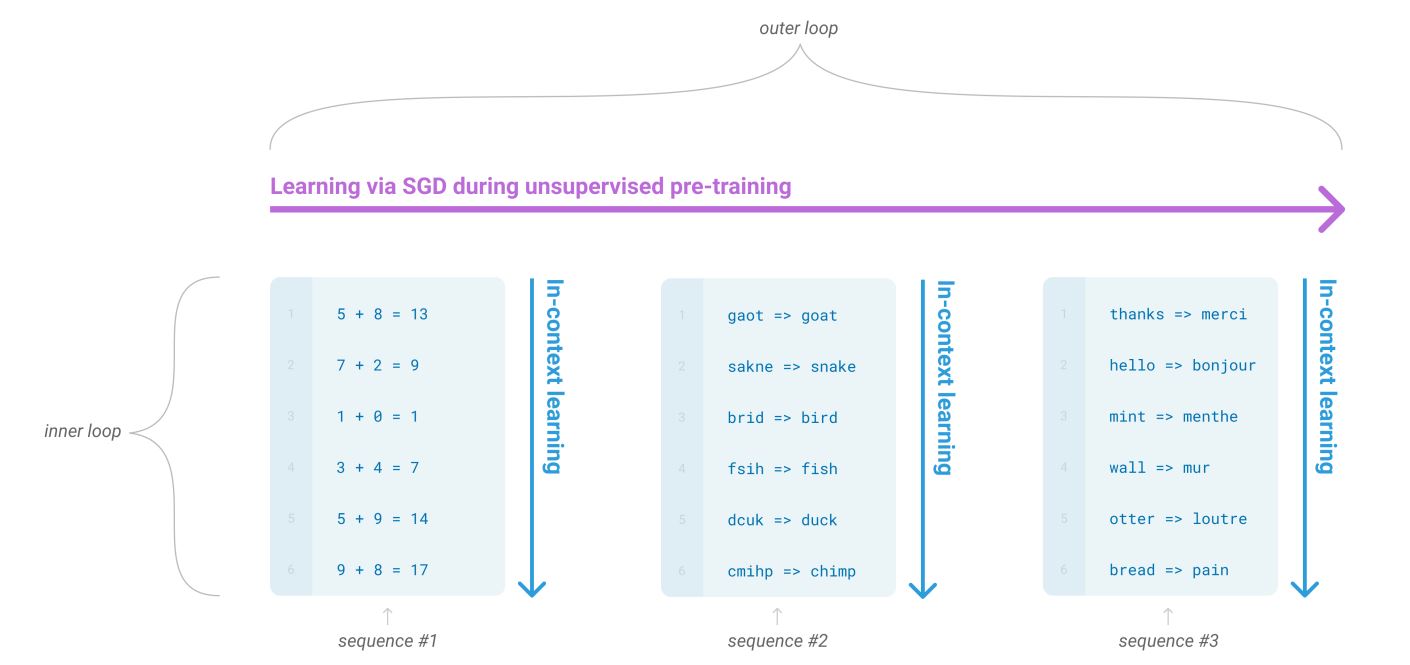
비지도 사전 학습 동안에는 언어 모델이 넓은 범위의 능력을 발달시키고, 추론 시 이러한 능력을 원하는 task로 적용시킵니다.
각 시퀀스로 forward-pass 하는 과정을 inner loop (In-Context learning) 라고 부르고, 전체 시퀀스로 사전 학습하는 과정을 outer loop 라고 부릅니다.
그림과 같이 단일 시퀀스 내에는 반복적인 sub-task가 포함되어 있습니다.
하지만, 이러한 방식은 여전히 fine-tuning 방식에 비해 좋지 못한 성능을 보였습니다.
언어 모델링의 최근 연구 경향은 모델 규모를 키워서 성능을 향상시키는 것이고, 이를 이용한다면 in-context learning의 성능도 향상시킬 수 있습니다.
논문에서는 이러한 가설을 실험하기 위해, 1750 억개의 파라미터를 갖는 autoregressive language model인 GPT-3를 학습시키고, in-context learning 능력을 측정하였습니다.
-
20개 이상의 NLP 데이터셋과 여러가지 새로운 tasks에서 GPT-3를 평가
-
3가지 방식으로 GPT-3 평가
-
few-shot learning
모델에게 10-100개 사이의 예시를 주는 방식
-
one-shot learning
모델에게 하나의 예시만을 주는 방식
-
zero-shot learning
모델에게 어떠한 예시도 주지 않는 방식
-
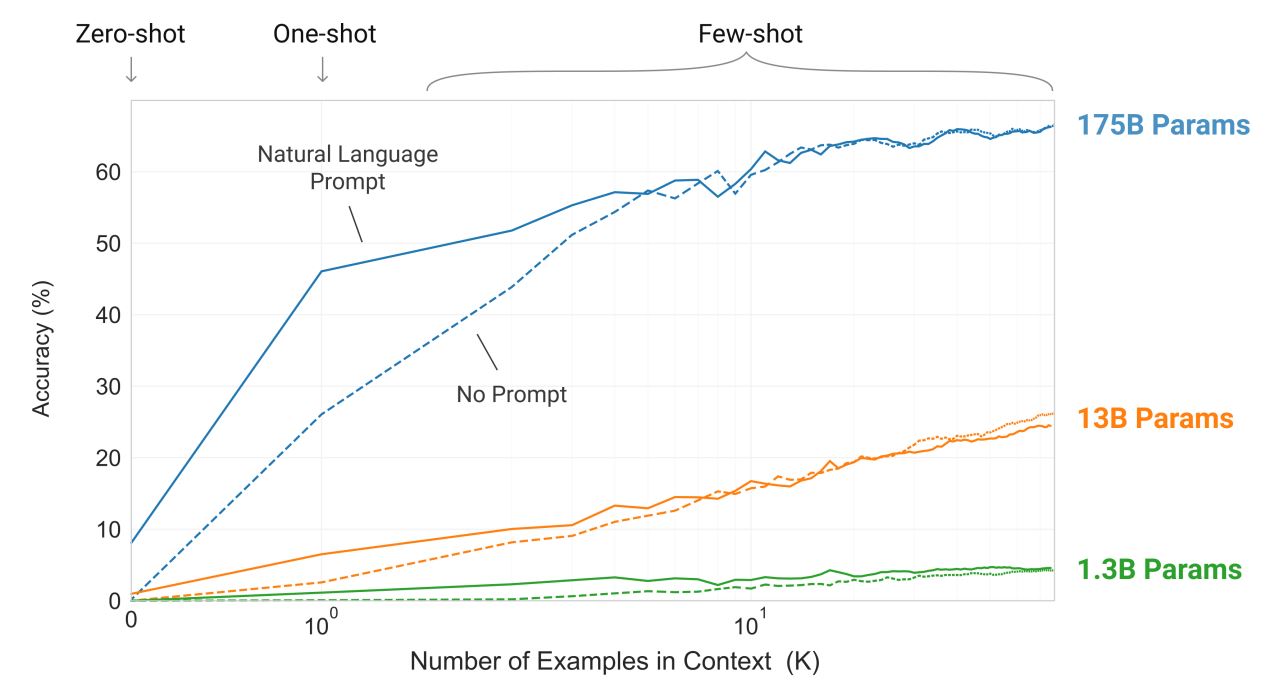
fig 1.2는 3가지 condition에 대한 결과이고, 모델이 단어로부터 관계없는 심볼들을 제거하는 단순한 task의 few-shot learning을 보여줍니다.
자연어 task 설명과 예시 개수(K)가 늘어날수록 모델 성능이 향상됩니다.
또한, Few-shot learning은 모델 사이즈가 커짐에 따라 극적으로 성능이 향상됩니다.
해당 실험에서 어떠한 gradient update도 fine-tuning도 수행되지 않았고, 단순히 condition에 따라 성능이 달라지는 것입니다.
NLP task에서 GPT-3는 zero-shot, one-shot, few-shot settings은 기존 SOTA와 대등한 정도의 성능인 경우도 있고, 심지어 SOTA를 뛰어넘는 성능인 경우도 있었습니다.
-
GPT-3 on CoQA
-
zero-shot setting에서 81.5 F1
-
one-shot setting에서 84.0 F1
-
few-shot setting에서 85.0 F1
-
-
GPT-3 on TriviaQA
-
zero-shot setting에서 64.3% accuracy
-
one-shot setting에서 68.0% accuracy
-
few-shot setting에서 71.2 accuracy
-
GPT-3는 one-shot, few-shot을 통해 모델이 얼마나 빠르게 task에 적용되는지 보여줍니다.
또한, few-shot setting에서 GPT-3는 사람도 구분하기 어려울 정도의 가상의 뉴스 기사를 생성할 수 있습니다.
하지만, 매우 큰 규모의 모델에도 불구하고 여전히 좋은 성능을 내지 못하는 일부 task가 존재합니다.
ANLI dataset, RACE, QuAC
또한, 논문에서는 오염된 데이터에 대한 체계적인 실험을 수행하였습니다.
대규모 모델을 Common Crawl과 같은 데이터셋으로 학습시킬 때, 이는 웹에 존재하는 텍스트 데이터이기 때문에 test set의 데이터를 포함하고 있을 가능성이 존재합니다.
논문에서는 데이터의 오염을 측정하고, 왜곡 효과를 정량화하는 체계적인 도구를 개발하였습니다.
대부분의 데이터셋에서 데이터 오염으로 인한 영향이 거의 없었지만 일부 데이터셋에서 과장된 결과를 볼 수 있었고, 이는 공개하지 않거나 *로 표기해두었습니다.
추가적으로, 논문에서는 더 작은 규모의 모델들(125 million params ~ 13 billion params)을 학습시켜 GPT-3의 성능과 비교하였습니다.
모델의 규모가 커질수록 zero, one, few 간 성능의 차이가 점점 커지는 것을 볼 수 있었고, 큰 모델일수록 meta learners에 더 적합한 것을 알 수 있었습니다.
Approach
-
Fine-Tuning (FT)

최근 가장 많이 사용되는 방식이고, 사전 학습된 모델을 특정 task에 적용시키기 위해 supervised dataset으로 학습시키는 방식입니다.
일반적으로, 학습을 위해 수천에서 수십만개의 labeled examples이 필요합니다.
이 방식의 강점은 다양한 벤치마크 데이터셋에서 강력한 성능을 보인다는 점이지만, 모든 task에 대한 대규모 데이터셋이 필요하다는 단점이 존재합니다.
논문에서는 task-agnostic 성능에 초점을 두고 있기 때문에, GPT-3를 특정 task로 fine-tuning 하지 않습니다.
하지만, 다른 모델들처럼 fine-tuning이 가능하며 이는 좋은 성능을 낼 것 입니다.
-
Few-Shot (FS)

-
One-Shot (1S)

-
Zero-Shot (0S)
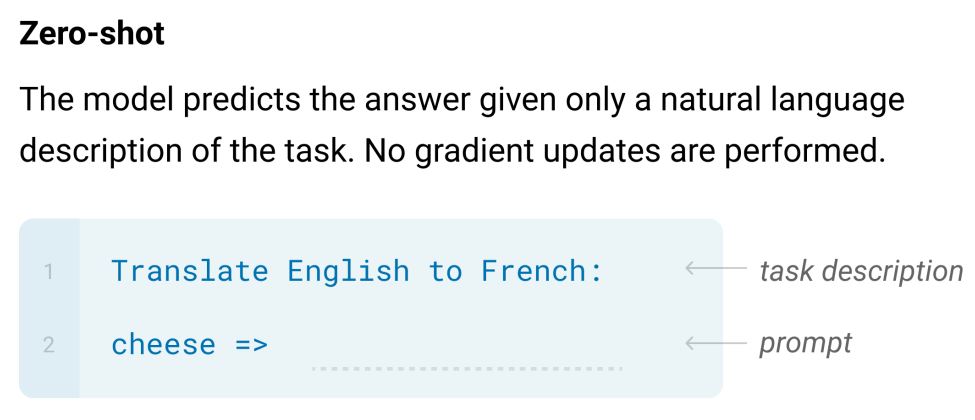
논문에서는 zero-shot, one-shot, few-shot에 집중하고 있습니다.
실험을 통해 few-shot 결과가 fine-tuned model의 SOTA와 근소한 차이를 보이는 것을 확인했습니다.
Model and Architectures
Leave a comment