
[Paper Review] Deep contextualized word representations
Deep contextualized word representations
Matthew E. Peters, Mark Neumann, et al. “Deep contextualized word representations” NAACL 2018.
Abstract
본 논문에서는 새로운 유형의 deep contextualized word representation을 제안
(1) 합성어, 의미론과 같이 단어 사용의 복잡한 특성을 모델링
(2) 다의어를 적절히 다루기 위해, 언어적 맥락에 따라 단어가 어떻게 사용되는지를 모델링
대규모 text corpus로 사전 학습된 deep bidirectional language model (biLM)의 내부적인 states를 활용하여 word vectors 학습
이러한 representations은 기존 모델에 쉽게 추가할 수 있고, 다양한 NLP task(question answering, textual entailment, sentiment analysis 등)에서 SOTA 성능을 향상시킴
또한 사전 훈련된 네트워크의 깊은 내부를 노출하는 것이 중요하다는 분석을 제시하고, downstream models이 다양한 유형의 semi-supervision signals를 혼합할 수 있도록 함
Introduction
neural language understanding models에서 사전 학습된 word representations은 핵심적인 요소이지만, 질 좋은 representations을 학습하는 것은 어려움
-
word representation을 위한 모델의 이상적인 2가지 능력
-
구문과 의미론과 같이 단어 사용의 복잡한 특성 모델링
-
다의어를 구분할 수 있도록 문맥에 따라 어떻게 단어가 달라지는지 모델링
-
본 논문에서는 이러한 두가지 challenges를 직접 해결한 새로운 유형의 deep contextualized word representation을 소개
2가지 모델링 능력 + 기존 모델과 쉽게 통합 가능 + 다양한 NLU task에서 SOTA 향상
각 토큰을 representation 할 때, 전체 입력 문장을 보고 표현된다는 점에서 전통적인 word embedding 방식과 다름
대규모 text corpus에 대해 LM objective와 결합되어 학습된 양방향 LSTM으로부터 나온 벡터를 사용함
이러한 이유로 제안한 representation을 ELMo(Embeddings from Language Models) representations이라고 부름
기존 워드 벡터 학습 방식과 달리, ELMo representations은 biLM의 내부 모든 layers를 활용하기 때문에 깊음
구체적으로, 본 논문에서는 task를 위한 각각의 입력 단어 위에 쌓인 벡터의 선형 결합을 학습하고, 이는 가장 상위 LSTM layer만 사용하는 것에 비해 매우 향상된 성능을 보였음
내부적인 states를 결합하는 것은 매우 풍부한 word representations을 만들어줌
higher-level LSTM states는 단어 의미릐 문맥 의존적인 면을 잘 파악하고, lower-level states는 문법적인 면을 잘 파악함
이러한 모든 신호들을 동시에 활용하는 것은 매우 유익하고, 학습된 모델이 최종적인 task에 가장 유용한 semi-supervision을 선택할 수 있도록 함
-
ELMo 실험 결과
ELMo representations은 실제로 잘 동작하는 것을 확인할 수 있었음
-
ELMo는 6개의 language understanding 문제를 위한 기존 모델들에 쉽게 추가될 수 있음
ex) textual entailment, question answering, sentiment analysis 등
-
ELMo representations의 추가는 SOTA를 상당히 향상시킴
직접적인 비교가 가능한 task에서 ELMo는 CoVe의 성능을 뛰어넘음
-
ELMo와 CoVe를 분석하는 과정에서 deep representations이 LSTM의 상위 layers만을 이용하는 것을 뛰어넘는다는 사실을 알아냄
-
또한, ELMo가 더 다양한 NLP task에서도 좋은 성능을 낼 것이라고 기대하고 있음
-
Related work
라벨이 없는 대규모 텍스트로부터 단어들의 구문론적, 의미론적 정보를 탐지하기 위해, 대부분의 SOTA NLP 모델들은 사전 학습된 word vectors를 사용함
하지만, 이러한 word vectors를 학습하는 방식들은 각 단어를 위한 문맥을 고려하지 않은 독립적인 representations을 생성함
이런 전통적인 word vectors의 단점을 극복하기 위해, subword 정보를 사용하거나 단어 의미에 따라 다르게 벡터를 학습시키는 방식들이 등장함
본 논문에서는 character convoluions을 사용하여 subword units의 이점을 얻고, multi-sense 정보를 downstream tasks로 통합시킴
-
character convoluion 이란
다양한 사이즈의 필터를 사용하여 컨볼루션 연산을 수행하고, 연산된 feautres를 합치는 것
참고 : https://arxiv.org/pdf/1508.06615.pdf
또 다른 연구들은 문맥 의존적인 representations을 학습하는 것에 초점을 맞춤
pivot 단어 주변의 문맥을 인코딩하기 위해 LSTM을 사용한 context2vec, pivot 단어 자체도 representation에 포함시키는 방식 등
본 논문에서는 풍부한 단일 언어 데이터를 활용하여 약 3천만 문장으로 구성된 corpus로 biLM를 학습시킴
deep contextual representations이 일반적이 잘 동작한다는 것을 실험을 통해 증명함
feature level에 따라 잘예측하는 분야가 있다는 것을 기존 연구들에서 증명함
ELMo representation을 위해 수정된 language model objective 도입하였고, downstream tasks를 위한 모델에 좋은 정보를 제공함
-
ELMo representations 사용법
라벨이 없는 데이터로 biLM을 사전 학습시킨 후 가중치를 고정시키고, 추가적인 task-specific model capacity를 부착하여 biLM representations을 활용할 수 있도록 함
ELMo: Embeddings from Language Models
널리 사용되는 워드 임베딩 방식과 달리, ELMo word representations은 전체 입력 문장의 기능을 함
내부 네트워크 states의 선형 함수(3.2 참고)로 character convoluions과 함께 2 layer biLMs의 상단에서 계산됨 (3.1 참고)
이러한 구조는 semi-supervised learning을 가능하게 함 (3.4 참고)
광범위한 neural NLP 구조와 쉽게 통합시킬 수 있음 (3.3 참고)
Bidirectional language models
-
forward LM
N개의 토큰으로 이루어진 시퀀스($t_1,t_2,…,t_N$)가 주어졌을 때, 순방향 언어 모델은 과거에 등장한 단어들을 기반으로 시퀀스의 확률을 계산
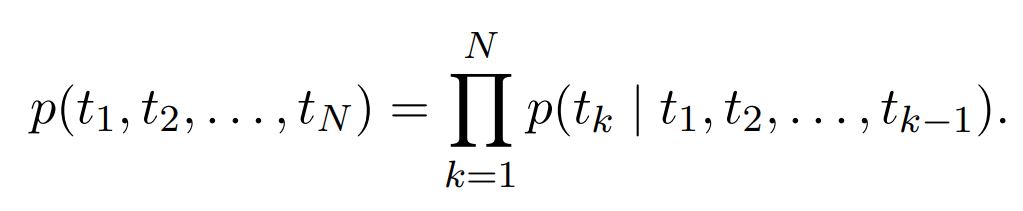
-
backward LM
다음에 등장하는 단어들을 기반으로 시퀀스의 확률을 계산
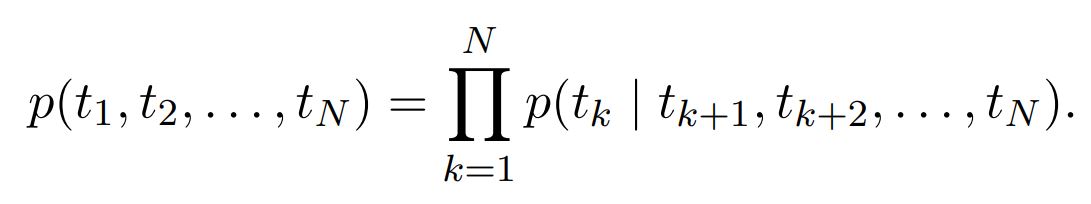
-
biLM
forward LM과 backward LM을 결합한 모델이고, 순방향과 역방향의 log likelihood를 공동으로 최대화시키는 방향으로 학습을 진행
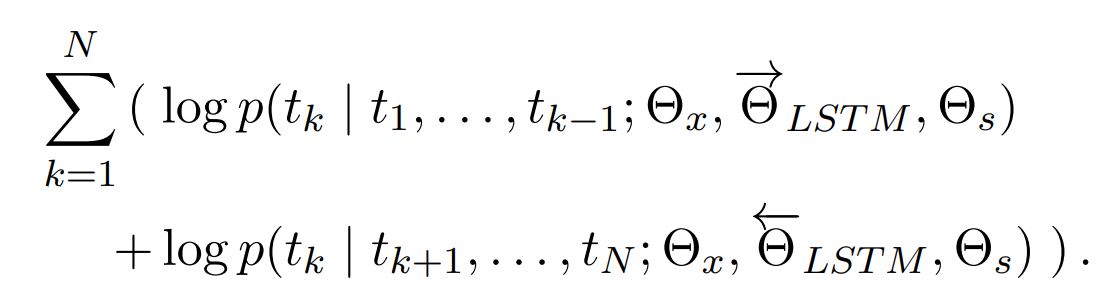
두 방향에서 LSTMs의 파라미터는 서로 분리되어 있지만, token representation ($\Theta_x$)과 Softmax layer ($\Theta_s$)의 파라미터는 묶여있음
ELMo
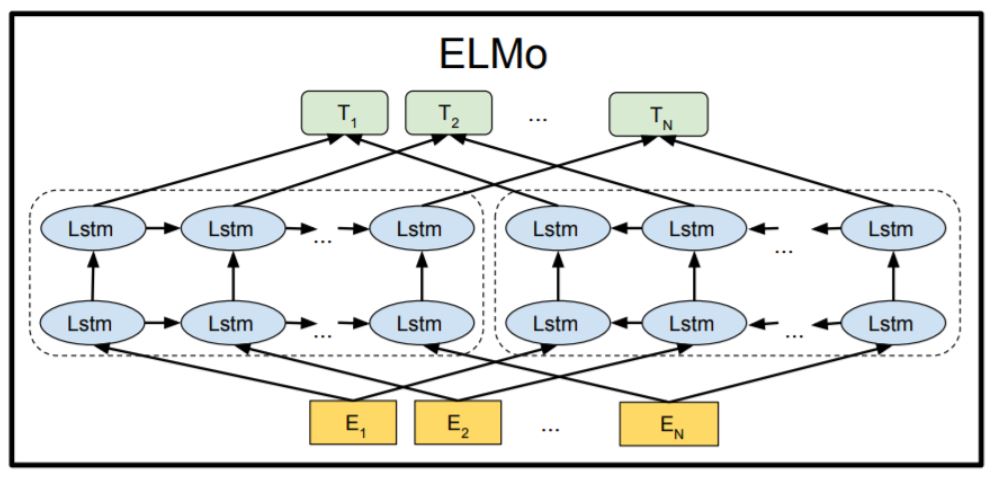
ELMo는 특정 task를 위해 biLM에서 중간 layer의 representations을 결합하는 구조
각 토큰 $t_k$에서 L-layer biLM은 2L + 1 representations의 집합을 계산함
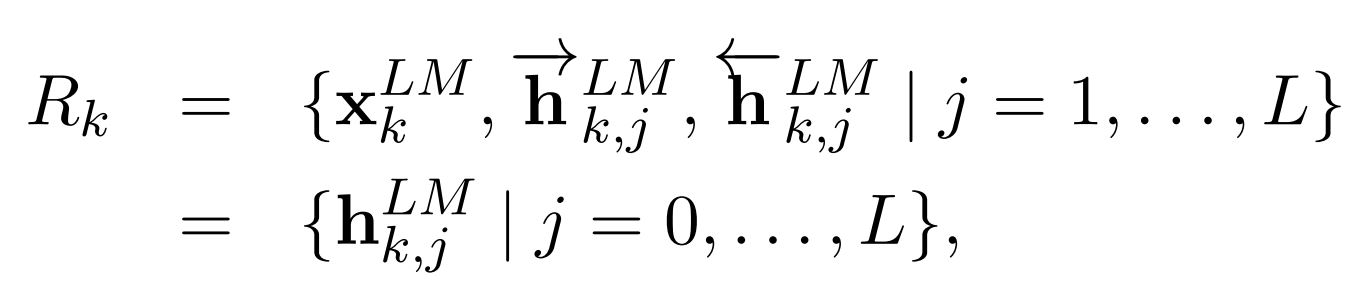
$h_{k,0}^{LM}$ : the token layer
$h_{k,j}^{LM}$ = $[h_{k,j}^{LM}\rightarrow;h_{k,j}^{LM}\leftarrow]$
downstream model로 포함되기 위해, ELMo는 모든 layers를 하나의 single vector로 만듦
가장 단순한 방법은 가장 상위 layer를 선택하여 사용할 수 있지만, ELMo는 좀 더 일반화된 벡터를 사용하기 위해 아래와 같은 식을 사용함
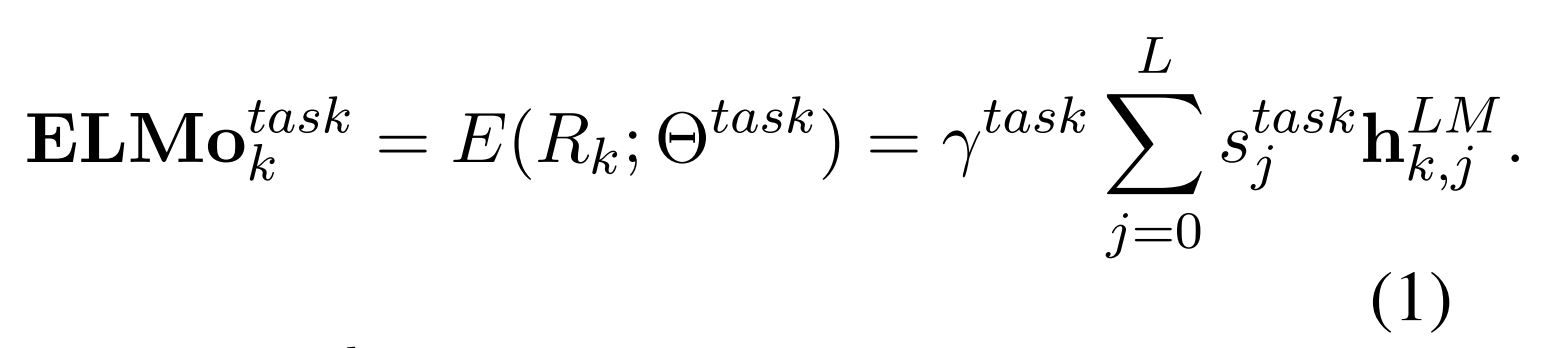
$\gamma^{task}$ : 전체 ELMo vector를 조정하기 위한 파라미터로 스칼라 값을 가짐 (최적화 과정을 도와주는 중요한 역할)
$s^{task}$ : softmax-normalized weights
Using biLMs for supervised NLP tasks
pre-trained biLM과 특정 NLP task를 위한 supervised architecture가 주어졌을 때, task model 성능을 향상시킬 수 있는 가장 단순한 과정임
-
biLM 이용하여 각 단어에 대한 모든 레이어의 representations을 저장
-
task를 위한 모델이 representations의 선형 결합을 학습하도록 함
대부분의 NLP 모델의 하위 계층 구조는 비슷하기 때문에 동일한 방식으로 ELMo를 부착할 수 있음
supervised model에 ELMo를 부착하기 위해 biLM의 가중치를 얼리고, ELMo vector $ELMo_{k}^{task}$와 $x_k$를 concatenation 하여 task RNN의 입력으로 넣어줌
SNLI, SQuAD와 같은 tasks에서 ELMo를 부착시킨 모델들의 성능이 부착하지 않은 모델들의 성능을 뛰어넘는 것을 확인함
또한, ELMo에 dropout과 regularization term을 추가했을 때 성능이 좋아지는 것을 확인할 수 있었음
Leave a comment