
[Paper Review] Star-net: a spatial attention residue network for scene text recognition
Star-net: a spatial attention residue network for scene text recognition
Liu, Wei, et al. “Star-net: a spatial attention residue network for scene text recognition.” BMVC. Vol. 2. 2016.
Abstract
본 논문에서는 텍스트 인식을 위한 새로운 모델인 SpaTial Attention Residue Network (STAR-Net) 제안
-
STAR-Net
자연적인 이미지에서 텍스트의 왜곡을 제거하는 공간적 변형을 수행하는 spatial mechanism으로 이루어짐
feature extractor가 왜곡으로 인해 잘못된 부분에 집중하는 것 없이 수정된 텍스트 영역에 집중할 수 있도록 도와줌
residue convolutional blocks을 이용하여 매우 깊은 feature extractor를 사용했고, 이를 통해 feature를 효과적으로 추출할 수 있었음 (discriminative text features)
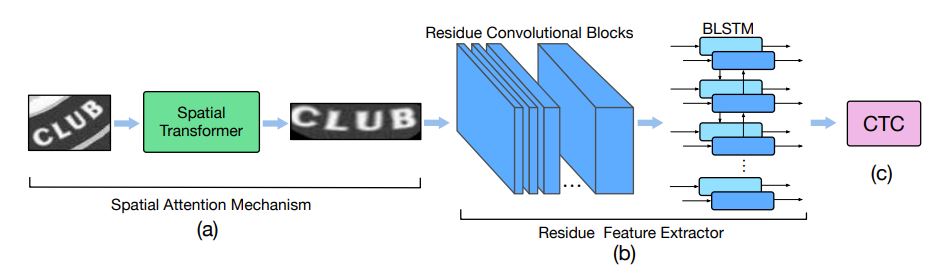
STAR-Net은 spatial attention mechanism과 residue convolutional blocks을 결합한 텍스트 인식을 위한 end-to-end neural network
-
STAR-Net performance
5개의 벤치마크 데이터셋에서 실험을 수행
왜곡이 적은 데이터셋에서는 SOTA와 비슷한 성능을 보였고, 왜곡이 심한 데이터셋에서는 SOTA를 뛰어넘는 성능을 보임
Introduction
Scene text recognition은 다양한 종류의 자연적인 이미지 속 텍스트를 인식하는 task이고, 많은 응용 분야에서 scene text 이미지에 포함된 풍부한 의미 정보의 이점을 누릴 수 있으로 많은 관심을 받음
응용 분야 : 자율 주행, 시각장애인을 위한 text-to-speech 기기, 이미지 번역

최근, 심한 왜곡이 없이 타이트하게 바운딩된 텍스트 이미지의 텍스트 인식은 큰 성장이 있었지만, 실제로는 심한 왜곡이 존재할 수 있고 텍스트가 이미지의 전체는 자치하고 있지 않음 (fig1 (a) 참고)
루즈하게 바운딩된 텍스트나 왜곡이 심한 텍스트를 잘 다룰 수 있는 인식 모델을 만드는 것은 여전히 해결되지 못한 문제임
텍스트 인식에서 공간적 왜곡을 다루는 것에 대한 연구는 상대적으로 많지 않음
-
공간적 왜곡을 다룬 기존 연구들
Phan et al.[30] : 원근감 있는 텍스트를 인식하기 위해 invariant feature로 SIFT descriptor 사용
SIFT 알고리즘 SIFT(Scale Invariant Feature Transform)는 이미지에서 Feature를 추출하는 대표적인 알고리즘 중의 하나입니다. 이미지의 scale(크기), Rotation(회전)에 불변하는 feature(특징)을 추출하기 때문에, 이미지가 회전해도 크기가 변해도 항상 그 위치에서 뽑히는 특징을 찾아냅니다. 참고 : https://intuitive-robotics.tistory.com/93본 논문에서 제안한 모델은 hand-crafted features를 이용하는 것 대신 이미지 변형을 위한 파라미터를 직접 출력하는 spatial attention mechanism을 이용함 (fig1 (b) 참고)
spatial attention mechanism은 텍스트 인식을 위해 왜곡된 텍스트를 적합한 모양으로 변형시킴
루즈하게 바운딩 된 텍스트나 왜곡이 심한 텍스트를 인식하는 것을 좀 더 쉽게 만들어줌
Shi et al.[33] : RNN 기반 attention model로 왜곡된 텍스트 영역을 다룸
입력 이미지에서 feature를 추출하고, 시퀀스에 대한 classification을 수행하는 방식으로 텍스트 인식을 다룸
본 논문에서 제안한 모델은 spatial attention mechanism과 residue learning 기법을 사용하여 이미지 기반 feature를 추출하는 방식
논문에서는 제한적이지 않은 scene text recognition을 위해 spatial attention mechanism을 이용하는 새로운 deep residue network 제안 (STAR-Net)
spatial attention을 도입하기 위해 spatial transformer module을 네트워크에 적용시켰고, 이는 모듈 이후 feature extractor가 텍스트 인식을 위한 좋은 features를 추출할 수 있도록 도와줌
또한, 최근 이미지 분류에서 residue learning이 성공적이었기 때문에 더 많은 convolutional layers를 쌓기 위해 residue convolutional blocks을 적용함
Contributions
-
spatial attention mechanism과 residue learning을 통합시킨 end-to-end로 학습이 가능한 STAR-Net
루즈한 텍스트 박스나 심한 왜곡이 있는 텍스트 박스에서 SOTA를 뛰어넘는 성능을 보여줌
-
spatial attention mechanism은 supervision 없이 텍스트 영역을 찾아내고 왜곡을 제거하도록 이미지를 변형시킴
왜곡을 제거하고 인식하기 쉬운 형태로 이미지를 변형시키기 때문에 다음 layer에서 좀 더 쉽게 feature를 추출할 수 있도록 도와줌
-
깊은 convolutional layers와 하나의 recurrent layer(BLSTM)으로 이루어진 residue convolutional blocks을 쌓아서 깊은 feature extractor를 만듦
Connectionist Temporal Classification(CTC) 알고리즘을 통해 최적화됨
Methodology
Spatial Transformer
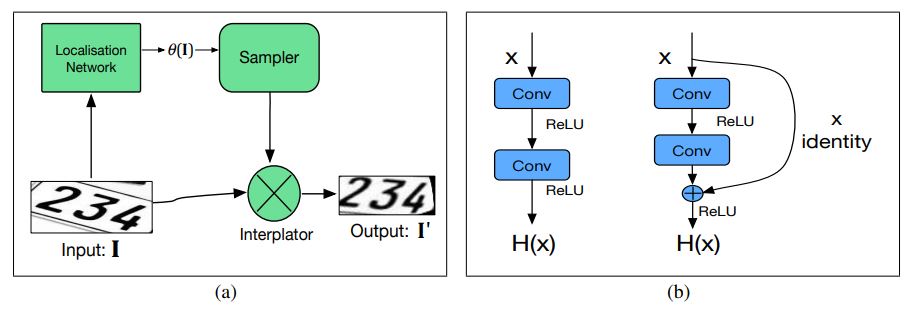
루즈하게 바운딩 되거나 왜곡된 텍스트 영역을 타이트하게 바운딩되고 수정된 텍스트 영역으로 변형시키는 역할이고, 다음 layer에서 변형된 텍스트 영역에 대해 discriminative features를 추출함
spatial transformer는 localisation network, sampler, interpolator 총 3가지 구성요소로 이루어짐
localisation network는 원본 텍스트 이미지 속 왜곡을 결정하고, 변형 파라미터를 출력함
sampler는 입력 이미지에서 추출할 텍스트 영역을 명시적으로 정의하는 샘플링 포인트를 찾아냄
interpolator는 샘플링 포인트에 가장 가까운 4개 픽셀의 강도 값을 보간하여 출력 이미지를 생성함
논문에서는 쉽게 설명하기 위해 affine transformation으로 아이디어를 설명함
[Localisation Network]
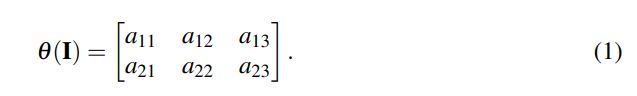
일반적인 CNN 구조이고, 최종 layer는 변형 파라미터를 예측하기 위한 regression layer로 이루어짐
변형 파라미터 예측을 위한 직접적인 지도는 하지 않고, 텍스트 인식 목적함수를 backpropagation 하는 과정에서 함께 학습됨
입력에 따라 적절한 변형을 수행하므로 변형 파라미터가 달라짐
[sampler]

출력 이미지를 위해 입력 이미지에서 샘플링 포인트를 찾아냄
[interpolator]
보간기는 샘플링 포인트에서 가장 가까운 4개 픽셀의 강도 값에서 출력 이미지 픽셀에 대한 강도 값을 생성함
bilinear interpolation을 이용하여 가장 가까운 4개 픽셀의 강도 값을 계산함
Residue Feature Extractor
강력하고 깊은 feature encoder 만들고 convolutional layers의 잠재력을 모두 활용하기 위해, 이미지 기반 features를 추출하기 위한 residue convolutional blocks과 시퀀셜 feautres 사이 long-range dependencies를 인코딩하기 위한 LSTM을 사용함
이미지 기반 features를 시퀀셜한 형태로 변환하기 위해, width $W_s$를 기준으로 슬라이싱함
$C_s \times H_s \times W_s$ -> $C_s \times H_s \times W_t$ , $t=[1,2,…,W_s]$
Residue Convoluional Block
2개의 convoluional lyaers와 2개의 ReLU, 입력과 두번째 convoluional layers의 출력 사이 shortcut connection으로 이루어진 residue block이 인코더에 사용됨 (fig3 (b) 참고)
일반적인 convoluional block의 경우:
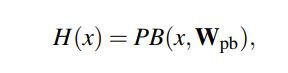
x를 입력으로 받아서 $H(x)$를 예측하기 위한 파라미터 $W_{pb}$를 학습해야 함
Residue convoluional block의 경우:
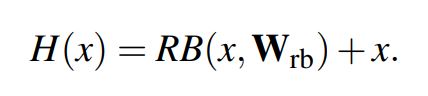
x를 입력으로 받아서 $H(x) - x$를 예측하기 위한 파라미터 $W_{rb}$를 학습해야 함
입력값을 제외한 잔여정보만을 학습하면 되기 때문에 최적화가 더 쉽고, degradation 문제를 피할 수 있음
Long Short-Term Memory
Long Short-Term Memory (LSTM)은 입력 시퀀스 features의 long-range dependencies를 학습할 수 있게 해주는 재귀적인 layer의 한 종류이고, memory block으로 구성되어 있음
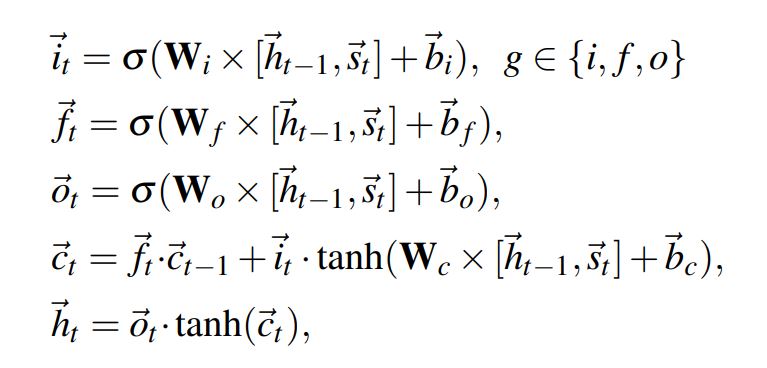
본 논문에서는 하나의 Bidirectional-LSTM layer을 사용함 (fig2 (b) 참고)
Leave a comment