
[Paper Review] Language models are unsupervised multitask learners
Language models are unsupervised multitask learners
Radford, Alec, et al. “Language models are unsupervised multitask learners.” OpenAI blog 1.8 (2019): 9.
Abstract
질의 응답(AQ), 기계 번역, reading comprehension, 요약과 같은 자연어 처리 task는 task에 맞는 데이터셋으로 지도 학습하는 접근법이 일반적입니다.
본 논문에서는 task에 대한 명시적인 지도없이 새로운 데이터셋인 WebText를 통한 학습만으로 다양한 task를 처리할 수 있는 언어 모델을 제시합니다.
-
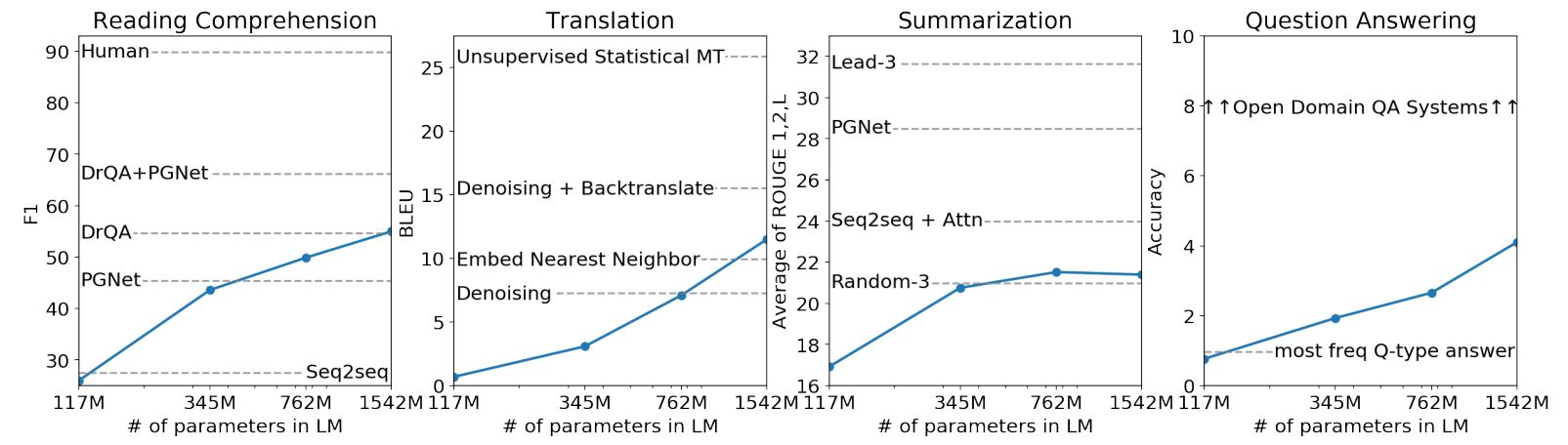
Question Answering
문서와 질문이 함께 입력으로 들어오면, 언어 모델이 정답을 생성하는 방식
CoQA 데이터셋 기준 55 F1 Score를 달성하였고, 이는 127,000 이상의 학습 데이터를 사용하지 않고 3~4개의 베이스라인 성능을 따라잡았습니다.
언어 모델의 용량은 zero-shot task의 성공을 위해 필수적이고, 이를 증가시키면 전반적인 tasks의 성능을 로그 선형에 비례하여 향상시킵니다.
GPT-2는 1.5B 파라미터를 갖는 트랜스포머로 논문에서 제안한 모델 중 가장 큰 모델이고, 8개 중 7개의 언어 모델링 데이터셋에서 zero-shot 환경에서 SOTA를 달성하였습니다.
하지만, GPT-2는 WebText에서 underfitting 현상을 보입니다.
Introduction
머신러닝 시스템은 대규모 데이터셋, 고용량 모델, 지도 학습의 결합으로 빠르게 성장해왔습니다.
하지만, 여전히 이러한 시스템은 데이터 분포의 작은 변화에도 매우 민감하고, task 제한적인 특성을 갖습니다.
현재 시스템은 전반적으로 잘하는 것 보다는 좁은 분야를 전문적으로 한다고 특징지을 수 있습니다.
본 논문에서는 다양한 tasks를 수행할 수 있는 더 일반적인 시스템을 만들고자 합니다.
각 task를 위해 학습 데이터셋을 구축하거나 라벨링할 필요없이 범용적으로 적용가능한 모델
-
일반적인 머신러닝 접근법
-
원하는 task를 위한 데이터셋 수집
-
수집한 데이터셋으로 모델을 학습
-
학습 데이터와 동일한 분포의 평가 데이터셋에서 모델을 평가
이러한 일반적인 접근방식은 특정 task만을 수행할 수 있고, 좁은 활용 범위를 가집니다.
그렇기 때문에 다양한 종류의 입력을 받는 captioning model, reading comprehension system, image classifier의 불규칙한 동작을 다루기에는 적합하지 않습니다.
-
본 논문에서는 단일 도메인 데이터셋으로 단일 task를 학습시키는 방식이 일반화 성능 부족의 원인이라고 추측하였습니다.
현재 구조를 기반으로 강력한 시스템을 만들기 위해서는 다양한 도메인과 task에 대해 학습하고, 성능을 평가해야 합니다.
최근, 이를 위한 GLUE, decaNLP와 같은 여러 벤치마크들이 제안되었습니다.
일반화 성능을 높이기 위한 시도
-
Multitask learning
일반적인 성능을 향상시키기 위해 등장한 유망한 프레임워크지만, 아직 연구 초기 단계입니다.
multitask learning을 위해서는 단일 task 보다 훨씬 많은 데이터셋을 필요로 하고, 현재 기술을 따라 잡을 정도로 데이터셋을 생성하고 그에 맞는 objectives를 고안하는 것은 어렵습니다.
[1] 현재 언어 tasks에서 가장 좋은 성능을 내는 시스템은 pre-training과 supervised fine-tuning을 결합한 방식입니다.
-
transfer learning 역사
-
학습된 단어 벡터를 task-specific 구조의 입력으로 활용
-
recurrent networks의 contextual representations 전이
-
최근에는 task-specific 구조가 필요하지 않고, 많은 self-attention blocks을 쌓은 구조(transformer)의 전이를 활용
-
이러한 방법론은 여전히 특정 task를 위한 지도 학습을 필요로 합니다.
[2] 다른 한편, 이용 가능한 데이터셋이 없을 때 특정 tasks(commonsense reasoning, sentiment analysis)를 수행하기 위한 연구들도 수행되었습니다.
본 논문에서는 [1],[2] 연구 방향을 연결하고, 더욱 일반적인 전이 방법을 제안합니다.
-
언어 모델이 추가적인 파라미터나 구조 변경 없이 zero-shot 환경에서 down-stream tasks를 수행할 수 있다는 것을 보여줍니다.
-
zero-shot 환경에서 다양한 tasks를 수행하면서 언어 모델의 능력을 강조하고, 앞으로의 가능성을 보여줍니다.
Approach
논문의 접근법의 핵심은 언어 모델링입니다.
-
Language modeling
다양한 길이의 심볼로 구성된 x의 집합인 $(x_1,x_2,…,x_n)$에서 비지도 분포 예측을 수행하는 것
언어는 자연적인 흐름이나 순서를 갖기 때문에 결합 확률을 조건부 확률의 곱으로 나타내는 것이 일반적입니다.
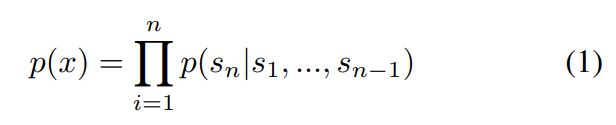
이러한 접근법은 어떤 형태의 조건부 확률에 대한 p(x)도 샘플링하기 쉽도록 만들어주었습니다.
최근에는 Transformer와 같은 self-attention 구조의 모델들이 등장하면서 이러한 조건부 확률을 계산하는 모델의 표현력이 크게 향상되었습니다.
단일 task 학습은 아래와 같은 조건부 확률로 표현할 수 있습니다.
\[p(output|input)\]단일 task 학습과 달리 일반적인 시스템은 다양한 tasks를 수행할 수 있어야 하기 때문에 동일한 입력이 들어오더라도 task에 따라 다른 출력값을 낼 수 있어야합니다.
\[p(output|input,task)\]-
Task conditioning 방법
-
architecture level
특정 task에 맞춰진 encoders 또는 decoders를 사용하는 방식
-
algorithmic level
MAML의 최적화 프레임워크
-
하지만, 언어는 심볼 시퀀스를 이용하여 task, 입력, 출력 모두를 구체화시킬 수 있는 유연한 방식을 제공합니다.
translation : (translate to french, english text, french text)
reading comprehension : (answer the question, document, question, answer)
McCann et al. (2018)은 이러한 포맷으로 다양한 task를 수행하고 추론할 수 있는 단일 모델을 학습시키는 것이 가능하다는 점을 제시하였습니다.
또한, 언어 모델링은 어떤 심볼이 예측되어야 할 출력인지에 대한 명시적이 지도없이 McCann의 tasks를 학습할 수 있습니다.
언어 모델링의 supervised objective는 unsupervised objective와 동일하기 때문에 global minimum 또한 동일합니다.
여기서 unsupervised objective 수렴시키기 위한 최적화가 가능한지가 가장 중요한 문제입니다.
예비 실험에서 충분히 큰 언어 모델이 multitask learning을 수행할 수 있다는 점을 확인하였지만, 명시적인 지도 학습 방식보다는 학습이 매우 느렸습니다.
Weston(2016)은 대화의 맥락에서 자연어를 직접 학습할 수 있는 시스템 개발의 필요성을 주장하였습니다.
이는 매력적인 접근법이지만, 매우 제한적일 수 있습니다.
인터넷은 상호작용 없이 쓰여진 방대한 양의 정보를 포함하고 있고, 논문에서는 충분한 용량의 모델이 이런 방대한 데이터를 활용한다면 좋은 성능을 낼 수 있을것이라 추측합니다.
본 논문에서는 다양한 tasks에서 zero-shot 환경으로 언어 모델의 성능을 분석하였습니다.
Training Dataset

논문의 접근 방식은 가능한 다양한 도메인과 컨텍스트에서 작업의 자연어 데모를 수집하기 위해, 가능한 크고 다양한 데이터 세트를 구축하려고 하였습니다.
Common Crawl과 같은 웹 스크랩에서 다양하고 제한되지 않은 텍스트를 이용할 수 있습니다.
이러한 저장소는 현재 언어 모델링 데이터셋 보다 수십 배는 더 크지만, 데이터 질이 보장되어 있지 않습니다.
따라서 질 좋은 데이터를 학습에 사용하기 위해, 텍스트를 필터링하여 WebText 데이터셋을 구성하였습니다.
-
Reddit에서 최소 3개 이상의 karma를 얻은 외부 링크를 스크랩
karma가 많이 얻은 링크일수록 흥미롭거나 교육적이거나 재밌는 링크일거라고 생각할 수 있음
-
4천 5백만 링크들의 텍스트를 포함
-
HTML response에서 텍스트만 추출하기 위해, Dragnet과 Newspaper content extractors를 결합하여 사용
-
실험에 사용된 데이터셋은 초기 버전으로 2017년 12월 이후의 링크들은 포함하고 있지 않음
-
중복 제거 및 일부 휴리스틱 기반 정리 후, 총 40GB의 텍스트에 대해 8 백만이 약간 넘는 문서가 포함됨
-
벤치마크 데이터셋에 위키피디아 문서를 포함하는 경우가 많기 때문에 공정한 평가를 위해 위키피디아 문서를 포함하는 텍스트는 모두 제거
Input Representation
일반적인 언어 모델(LM)은 모든 문자열에 대한 확률값을 계산할 수 있어야합니다.
현재 가장 크기가 큰 언어모델은 다양한 전처리 과정을 포함하고 있고, 이런 전처리 과정은 모델이 사용가능한 문자 공간을 제한시킵니다.
lower casing, tokenization, out-of-vocabulary tokens
최근에는 바이트 단위 LM이 단어 단위 LM 보다 좋은 성능을 보이고 있고, 본 논문에서도 WebText에 대해 바이트 단위 LMs으로 학습하였을 때 비슷한 성능 향상 차이를 확인할 수 있었습니다.
Byte Pair Encoding (BPE)은 문자 단위와 단어 단위의 중간 단위를 사용하고, 빈번하게 등장하는 시퀀스는 단어 단위, 드물게 등장하는 시퀀스는 문자 단위로 토큰화합니다.
본 논문에서는 바이트 단위로 인코딩한 BPE를 사용하고, 특정 단어의 비슷한 변형이 추가되는 것을 방지하기 위해 모든 바이트 시퀀스와 문자 사이 병합을 방지하였습니다.
[변형 예시]
dog -> dog. dog? dog!
Model
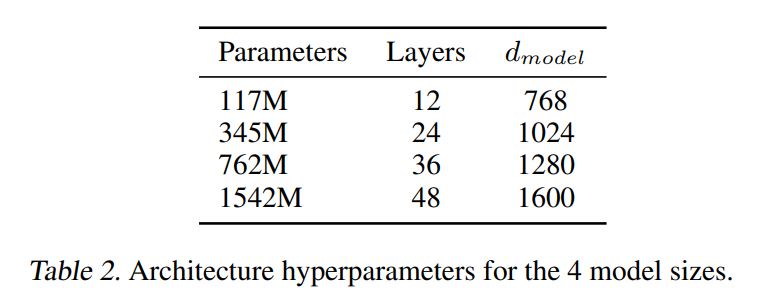
가장 작은 크기의 모델이 기존 GPT-1과 동일한 크기이고, 두번째로 작은 크기의 모델의 BERT large와 동일한 크기입니다.
가장 큰 크기의 모델이 GPT-2이고, 기존 GPT 대비 10배 이상의 파라미터로 이뤄어져 있습니다.
트랜스포머 기반 구조를 사용하였습니다.
아래의 사항을 제외하고 모델의 세부적인 구조는 OpenAI GPT 모델을 따릅니다.
-
Layer normalization이 각 sub-block의 입력으로 옮겨지고, 최종적인 self-attention block 뒤에 layer normalization이 추가되었습니다.
-
초기화 방식이 수정되었습니다.
residual layers의 가중치의 초기값을 $1 \over \sqrt{N}$로 조정합니다.
N은 residual layers의 개수입니다.
-
Vocabulary size, context size, batch size를 모두 증가시켰습니다.
vocabulary 사이즈가 50,257, context size가 512에서 1024 tokens으로 증가, batch size가 512로 증가
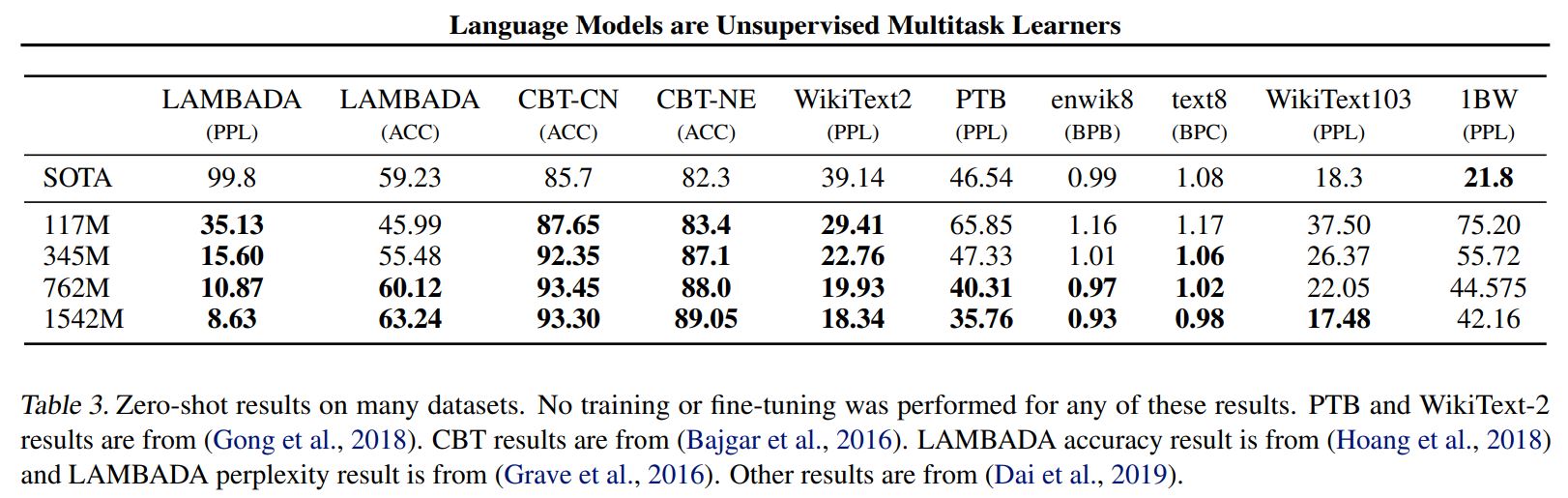
Experiments
Leave a comment