
[Paper Review] Exploring the limits of transfer learning with a unified text-to-text transformer
Exploring the limits of transfer learning with a unified text-to-text transformer
Raffel, Colin, et al. “Exploring the limits of transfer learning with a unified text-to-text transformer.” J. Mach. Learn. Res. 21.140 (2020): 1-67.
Abstract
자연어 처리에서 데이터가 풍부한 task로 모델을 pretraining 하고 downstream task로 fine-tuning 하는 Transfer learning 기법이 널리 사용되었고, 다양한 접근 방식, 방법론이 등장하였습니다.
본 논문에서는 모든 text 기반 언어 문제를 text-to-text 형태로 변환한 통합된 프레임워크를 소개하고, NLP의 다양한 transfer learning 기법들을 탐구하였습니다.
수십 가지 자연어 이해 task에 대한 pretraining objectives, 모델 구조, unlabeled data sets, transfer 방식, 이외에도 다양한 요소들을 비교
실험을 통해 얻은 통찰력과 모델 scaling, 새로운 데이터셋 “Colossal Clean Crawled Corpus”를 결합하여 요약, QA, 텍스트 분류 등 많은 벤치마크에서 SOTA 성능을 달성하였습니다.
논문 저자들은 NLP의 transfer learning 차후 연구들이 활용할 수 있도록 데이터셋과 pre-trained models, 코드를 공개하였습니다.
1. Introduction
최근에는 데이터가 풍부한 task로 전체 모델을 사전 학습시키는 방식이 많이 사용되고 있고, 사전 학습은 모델이 downstream tasks로 전이되기 위한 범용적인 능력과 지식을 발전시킬 수 있도록 합니다.
-
컴퓨터 비전 분야의 사전 학습
라벨이 있는 대규모 데이터셋(ImageNet)을 활용하여 supervised learning 방식으로 pretraining 수행
-
자연어 처리 분야의 사전 학습
라벨이 없는 데이터를 활용하여 unsupervised learning 방식으로 pretraining 수행
NLP의 unsupervised pre-training은 인터넷에서 대규모 텍스트를 얻을 수 있기 때문에 특히 매력적인 방식입니다.
the Common Crawl project : 매달 웹 페이지를 통해 추출된 20TB 텍스트를 생성
뉴럴 네트워크는 큰 데이터셋에서 큰 모델을 학습시킬수록 성능을 좋아지는 특성을 갖고 있기 때문에 대규모 데이터를 활용할 수 있다는 것은 큰 이점이 될 수 있습니다.
이러한 효과로 NLP에 다양한 전이 학습 방법론이 발전하면서 방대한 양의 연구들이 등장하였고, 이는 다양한 pre-training objectives, unlabeled datasets, benchmarks, fine-tuning 방법 등을 만들어냈습니다.
해당 분야가 급속도로 성장하면서 다른 알고리즘을 비교하고, 새로운 기여의 효과를 분석하고, 전이 학습을 위한 기존 방법들을 이해하는 것이 어려울 수 있습니다.
논문에서는 더욱 엄밀한 이해를 위해 전이 학습을 위한 통합된 접근법을 활용하였고, 이를 통해 다양한 접근법을 체계적으로 연구하고 현재 접근법의 한계점을 실험하였습니다.
본 논문의 근원적인 아이디어는 모든 텍스트 처리 문제를 텍스트를 입력으로 받고 새로운 텍스트를 출력하는 text-to-text 문제로 다루는 것입니다.
이러한 접근법은 NLP tasks에 기존 통합 프레임워크들에서 영감을 얻었습니다.
모든 텍스트 문제를 question answering 문제 or language modeling 문제 or span extraction 문제로 해결한 기존 연구들에서 영감을 얻음
결정적으로, text-to-text 프레임워크를 사용하면 논문에서 고려한 모든 task에 대해 모델, objective, 학습 절차, 디코딩 과정을 동일하게 적용할 수 있습니다.
question answering, document summarization, sentiment classification, to name a few 등을 포함하는 다양한 영어 기반 NLP tasks에서 성능을 평가
통합된 프레임워크를 사용하여 다양한 전이 학습 objectives, unlabeled datasets과 다른 요소들의 효과를 비교하고, 모델과 데이터셋의 규모를 조정하면서 NLP 전이 학습의 한계를 탐구할 수 있었습니다.
논문의 목표는 새로운 방식을 제안하는 것이 아니고, 해당 분야에 대한 포괄적인 관점을 제공하는 것이며 기존 기법들을 조사하고 탐구하여 실험을 통해 비교하는 내용으로 논문이 구성되어 있습니다.
-
scaling up
기존 접근법들의 한계를 알아보기 위해 다양한 모델 사이즈를 실험했고, 110억개의 파라미터를 갖는 모델로 많은 task에서 SOTA 성능을 달성하였습니다.
-
Colossal Clean Crawled Corpus (C4)
웹에서 추출된 수백 기가바이트의 정제된 영어 텍스트로 구성된 새로운 데이터셋을 소개하였습니다.
2. Setup
광범위한 실험 결과를 제시하기 전, Transformer 구조와 downstream tasks 등을 포함한 실험 결과를 이해하기 위해 알아야 할 필수적인 주제에 대해 설명합니다.
또한, text-to-text task로 모든 task를 해결하는 접근법을 소개하고, unlabeled text dataset으로 이용하기 위해 제작한 Clossal Clean Crawled Corpus (C4)에 대해 설명합니다.
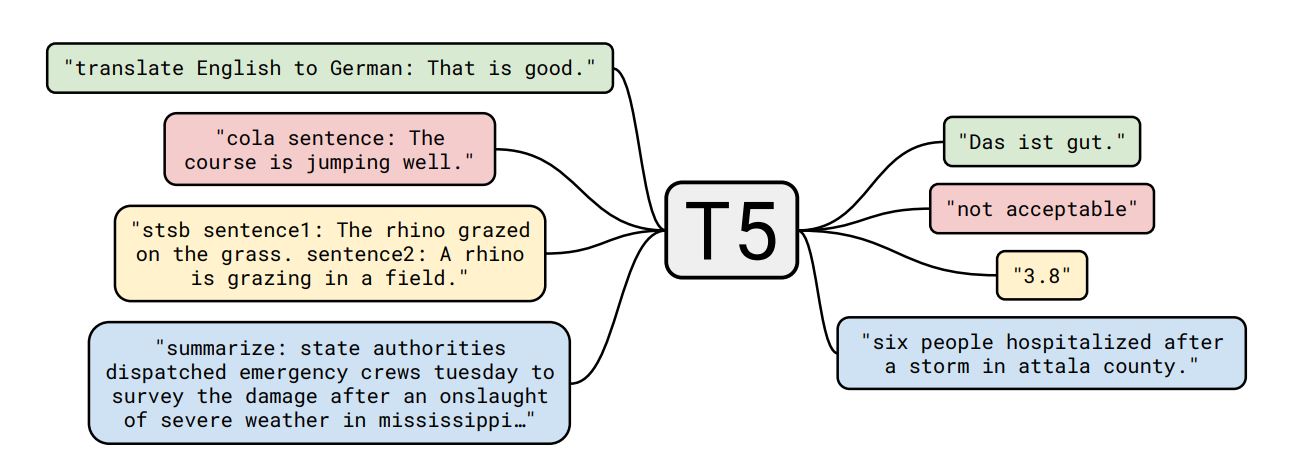
논문에서 제시하는 모델과 프레임워크를 Text-to-Text Transfer Transformer(T5) 라고 부릅니다.
2.1 Model
초기에는 전이학습을 위해 RNN을 이용하였지만, 최근에는 트랜스포머 기반 모델들이 많이 사용됩니다.
트랜스포머는 초기 기계번역에서 효과적인 결과를 보였고, 차후 다양한 NLP 분야에서 사용되고 있습니다.
논문에서 실험한 모델들도 모두 트랜스포머 기반 모델들이고, 세부적인 구현내용은 3.2절에서 언급한 부분말고는 기존 모델구조에서 변경하지 않았습니다.
-
self-attention
트랜스포머에 쌓는 블록을 구성하는 주된 요소이고, 어텐션을 통해 입력 시퀀스 요소를 시퀀스 내 모든 요소들과의 가중 평균으로 대체하여 처리합니다.
-
encoder-decoder
트랜스포머는 인코더-디코더 구조로 시퀀스 투 시퀀스 tasks에 최적화되어 있습니다.
최근에는 언어 모델링, 분류, span prediction과 같은 다양한 task를 해결하기에 적합한 트랜스포머의 인코더 또는 디코더만을 이용한 다양한 모델들이 등장하였습니다.
논문에서 구현한 encoder-decoder Transformer 구현은 기존 Transformer 논문 구현과 거의 동일합니다.
-
Transformer Encoder
입력 시퀀스를 임베딩하고, 인코더의 입력으로 넣어줍니다.
인코더는 self-attention layer와 small feed-forward network로 구성된 블록으로 쌓은 구조이고, 각 구성요소의 입력에 대해 Layer normalization을 적용합니다.
여기서 layer normalization은 추가적인 bias가 없이 조정을 수행하는 단순한 버전으로 사용하였습니다.
layer normalization을 수행한 후, residual skip connection을 통해 입력을 출력에 더해줍니다.
또한, feed-forward network 내부에는 dropout을 적용합니다.
-
Transformer Decoder
디코더의 구조는 인코더의 출력값과 디코더의 입력값 사이 어텐션을 수행하는 부분을 제외하면 인코더와 비슷합니다.
디코더의 self-attention은 모델이 오직 과거의 출력값만을 볼 수 있도록 autoregressive 방식이나 casual self-attention 방식을 사용합니다. (치팅 방지)
최종적인 디코더 블록의 출력은 소프트맥스를 갖는 dense layer로 들어가게 되고, 여기서 가중치는 입력 임베딩 matrix와 공유됩니다.
모든 어텐션 메커니즘은 독립적인 head로 나누어지고 (multi-head attention), 모든 head의 출력값을 concateneation 하여 최종적인 예측을 수행합니다.
-
Position embeddings
트랜스포머의 self-attention은 연산을 수행할 때 순서를 전혀 고려하지 않습니다. 따라서 입력 시퀀스의 순서를 고려할 수 있도록 정보를 제공하기 위해 position embedding을 사용합니다.
최근에는 각 위치에 대해 고정적인 임베딩을 부여하는 방식이 아닌 학습된 임베딩 값을 사용하는 relative position embeddings이 사용되고 있습니다.
논문에서는 각 임베딩이 스칼라값을 갖는 단순한 형태의 position embedding을 사용하였고, 계산 효율을 위해 모든 레이어간 position 임베딩 파라미터를 공유하였습니다.
논문에서 구현한 트랜스포머는 Layer Norm bias를 제거한 것, layer normalization을 residual path 밖에 둔 것, 다른 position embedding 방식을 사용한 것을 제외하면 기존 트랜스포머 구현과 동일합니다.
또한, 논문에서는 모델의 확장성을 실험하기 위해 모델의 크기와 데이터셋의 크기를 조절하며 다양한 실험을 수행했습니다.
큰 모델은 상당한 연산량을 필요로 하기 때문에 하나의 머신에서 실험할 수 없어서 모델과 데이터의 병렬화를 사용하여 학습하였습니다.
2.2 The Colossal Clean Crawled Corpus
NLP 전이학습에 대한 기존 연구들은 비지도 학습 방식으로 라벨이 없는 대규모 데이터셋을 사용합니다.
본 논문에서는 라벨이 없는 데이터의 질, 특성, 규모에 따른 효과를 측정하고자 합니다.
논문 저자들의 조건을 충족하는 데이터셋을 만들기 위해, Common Crawl를 활용하였습니다.
Common Crawl은 기존에도 NLP 데이터셋으로 활용된 적이 있음
Common Crawl은 공개적으로 이용가능한 웹 아키이브이고, markup과 텍스트가 아닌 내용을 제거하여 웹에서 텍스트만을 추출할 수 있도록 제공합니다.
매달 약 20TB 텍스트가 생성되지만, 텍스트의 대부분은 자연어가 아니기 때문에 불필요한 텍스트를 정제하여 데이터셋으로 사용하였습니다.
-
물음표, 느낌표, 큰 따옴표, 온점과 같이 구두점으로 종료되는 문장만을 사용
-
5 문장 보다 적은 문장으로 구성된 페이지를 제거하고, 최소 3 단어가 포함된 문장만을 사용
-
부적절한 단어가 포함된 페이지를 제거
외설적인 내용이나 욕설과 같은 단어들이 포함된 페이지 제거
-
“lorem ipsum”이 포함된 페이지 제거
lorem ipsum은 출판이나 그래픽 디자인 분야에서 그래픽 요소나 시각적 연출을 보여줄 때 사용하는 표준 채우기 텍스트로, 최종 결과물에 들어가는 실제적인 문장 내용이 채워지기 전에 시각 디자인 프로젝트 모형의 채움 글로도 이용된다. 즉, 의미없이 채워진 텍스트로 모델이 학습하기에 적절하지 않는 문장이다. 참고 : https://ko.wikipedia.org/wiki/%EB%A1%9C%EB%A0%98_%EC%9E%85%EC%88%A8 -
{ or } 가 등장하는 페이지 제거
자바 스크립트와 같은 프로그래밍 언어에서 자주 쓰이는 것으로 자연어로 이루어진 텍스트가 아닐 가능성이 높기 때문에 제거
-
중복된 텍스트를 제거하기 위해, 2번 이상 발생하는 3 문장 단위를 모두 제거
추가적으로, 모든 downstream tasks가 모두 영어 기반 텍스트이기 때문에 langdetect을 통해 영어로된 페이지를 필터링하여 사용하였습니다.
Common Crawl를 데이터로 사용한 기존 연구들도 언어 디텍터 사용, 짧은 문장, 중복된 문장을 버리는 필터링을 수행하였지만, 공개되지 않은 필터링을 수행했다는 점, Creative Commons content 만을 이용했다는 점, 특정 task에 초점을 맞춰둔 데이터라는 점 등 제한적인 특성때문에 새롭게 데이터셋을 구성하였습니다.
본 논문에서는 기본 데이터셋을 구축하기 위해 2019년 4월부터 웹 텍스트를 다운로드 받았고, 이전에 언급한 필터링을 적용하였습니다.
-
Colossal Clean Crawled Corpus (C4)
일반적으로 사용하는 사전 학습 데이터셋 보다 10배 정도 큰 크기이고 (약 750G), 정제된 영어 텍스트로 구성되어있습니다.
해당 데이터셋은 TensorFlow Datasets으로 공개되어 있습니다.
2.3 Downstream Tasks
본 논문의 목표는 일반적인 언어 학습 능력을 측정하는 것이고, 이를 위해 다양한 벤치마크 데이터셋에서 downstream 성능을 연구하였습니다.
machine translation, question answering, abstractive summarization, text classification
연구를 위해 사용한 벤치마크 데이터셋은 아래와 같습니다.
-
the GULE, SuperGLUE text classification meta-benchmarks
실험의 편의를 위해, GLUE/SuperGLUE 모든 task의 데이터셋을 합쳐서 단일 task로 fine-tuning 하였습니다.
-
CNN/Daily Mail abstractive summarization
-
SQuAD question answering
-
WMT English to German, French, and Romanian translation
2.4 Input and Output Format
위에서 언급된 다양한 task의 데이터셋을 단일 모델에 학습시키기 위해, 고려하는 모든 task를 text-to-text 포맷으로 변경시켰습니다.
text-to-text format 이란?
모델의 입력으로 텍스트가 들어가고, 출력으로도 텍스트가 나오는 형태
text-to-text 포맷을 이용하는 경우, 모델의 사전 학습과 미세 조정 과정에서 사용하는 objective function을 일관성 있게 만들어줍니다.
구체적으로, 모델은 maximum likelihood objective로 teacher forcing을 적용하여 학습됩니다.
Leave a comment