
[Paper Review] Efficient Estimation of Word Representations in Vector Space
Efficient Estimation of Word Representations in Vector Space
Mikolov, Tomas, et al. “Efficient estimation of word representations in vector space.” arXiv preprint arXiv:1301.3781 (2013).
Abstract
-
매우 큰 데이터셋으로부터 단어들의 연속적인 벡터 representations을 계산하기 위한 2가지 모델 제안
모델의 representations 결과를 word similarity task에서 평가하였고, 기존의 neural networks 기반 다른 모델들과 비교함
-
매우 낮은 계산비용으로 정확도에서 큰 향상을 보임
16억개의 단어들의 구성된 대규모 데이터셋에서 word vector를 학습시키는데 하루가 걸리지 않음
Introduction
-
현재 많은 NLP 시스템과 기술들은 단어들을 독립적으로 처리함 (단어간 유사도를 고려하지 않음)
단어를 독립적으로 처리하는 이유
단순하지만 매우 잘동작함
대규모 데이터로 학습시킨 단순한 모델들이 적은 데이터로 학습시킨 복잡한 시스템보다 성능이 우수함
-
하지만, 이런 단순한 방식은 다양한 tasks에서 한계점이 존재함
automatic speech recognition, machine translation 등 대규모 데이터셋을 구하기 힘든 task에서 한계에 부딪힘
-
최근 머신러닝 기술들의 발전하면서 대규모 데이터셋에서 복잡한 모델을 학습시키는 것이 가능해졌고, 이는 일반적으로 단순한 모델의 성능을 뛰어넘음
-
분산 표현(Distributed Representation)을 사용하는 것이 가장 성공적임
예를 들어, 신경망 기반 언어 모델은 N-gram 모델을 훨씬 능가함
분산 표현이란? 분산 표현은 분포 가설을 이용하여 텍스트를 학습하고, 단어의 의미를 벡터의 여러 차원에 분산하여 표현
https://wikidocs.net/22660
Goals of the Paper
-
10억개 이상의 단어들과 vocabulary에서 100만개 이상의 단어들을 가진 대규모 데이터로부터 질좋은 단어 벡터들을 학습시키기 위한 기법들을 소개함
현재까지는 몇 억 단어 이상의 대규모 데이터셋에서 성공적으로 학습시킨 모델이 제안된 적 없음
-
vector representations 결과를 평가하기 위해 가장 최근 제안된 기술들을 사용
유사한 단어가 서로 가까이 있을 것이고, 단어들 사이에 여러 수준의 유사성을 가질 수 있다고 기대함
-
단어 representations의 유사성은 단순한 구문 규칙들을 넘어선다는 점이 발견됨
vector(‘King’) - vector(‘Man’) + vector(‘Woman’) = ‘Queen’
-
단어들 사이에 선형 규칙들을 보존하는 새로운 모델을 개발하여 벡터 연산의 정확도를 높이기 위해 노력함
-
구문 규칙성과 의미적 규칙성을 둘 다 측정하기 위한 새로운 테스트셋 제작하고, 이러한 규칙성이 높은 정확도로 학습될 수 있음을 보임
-
학습시간과 정확도가 단어 벡터의 차원과 학습 데이터의 양에 얼마나 의존적인지에 대해 논의함
Previous Work
-
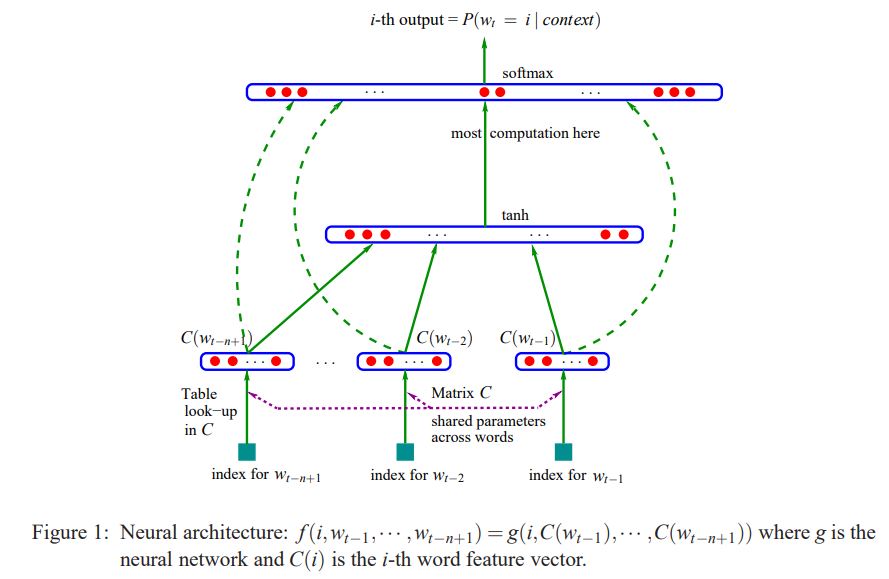
연속적인 벡터로 단어들을 표현하는 방식은 오랜 역사를 가짐 (NNLM : neural network language model)
-
가장 유명한 모델은 “A neural probabilistic language model”
하나의 linear projection layer와 하나의 non-linear hidden layer를 가진 feedforward neural network가 단어 벡터 representation과 통계적 언어 모델을 공동으로 학습시키기 위해 사용됨
-
또 다른 흥미로운 NNLM 모델은 하나의 hidden layer를 가진 neural network를 사용하여 단어 벡터를 학습하고, 학습된 단어 벡터가 NNLM을 학습시키기 위해 사용되는 two-step 모델
연구에서 이러한 구조를 확장하였고, 첫번째 step에 초점을 둠
-
단어 벡터가 많은 NLP 응용 프로그램을 개선하고 단순화하는 데 사용될 수 있음이 밝혀지면서, 단어 벡터 추정이 다양한 모델을 사용하여 수행되고 다양한 말뭉치에 대해 학습됨
하지만, 이런 구조는 대각 가중치 행렬이 사용되는 log-bilinear 모델의 특정 버전을 제외하면, 훨씬 더 많은 계산 비용이 듦
Model Arichitectures
-
Latent Semantic Analysis(LSA), Latent Dirichlet Allocation(LDA)과 같이 연속적인 단어들의 representations을 추정하기 위한 다양한 타입의 모델들이 제안됨
-
이 논문에서는 neural networks로 학습된 단어들의 분산 표현에 집중하였고, 이는 단어들 사이 선형적 규칙을 보존하기 위한 LSA보다 상당히 잘 동작함
LDA는 대규모 데이터셋에서 계산이 비용이 매우 크다는 문제가 있음
-
다른 모델들과 비교하기 위해, 파라미터 수에 의한 계산 복잡도를 먼저 정의하고, 그 뒤에 계산 복잡도를 최소화하면서 정확도를 높이기 위해 노력할 것임
-
학습 복잡도는 아래 식을 이용하여 정의함
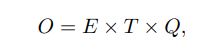
E:epochs / T : training set에서의 단어들의 수 / Q : 각 모델 구조에 따라 정의
일반적인 셋팅은 E = 3-50, T는 10억 개이며, 모든 모델들은 SGD와 backpropagation을 사용하여 학습됨
Feedforward Neural Net Language Model (NNLM)
-
확률적 feedforward neural network 언어 모델은 “A Neural Probabilistic Language Model”에서 제안됨
input, projection, hidden, output layer로 구성
input layer에서 N 개의 이전 단어들이 1-of-V coding(V:vocabulary의 크기)을 사용하여 인코딩(one-hot encoding)되고, 이는 공유된 projection matrix를 이용하여 projection layer P(NxD 차원을 가짐)로 projection 됨
모든 시간에 오직 N 개의 입력만 활성화 되므로, projection layer의 구성은 상대적으로 연산량이 낮음
-
NNLM 구조에서 projection layer에서 값들이 많아지면, projection layer와 hidden layer 사이 연산량이 증가함
일반적 셋팅은 N=10, projection layer(P)는 500-2000, hidden layer size H는 보통 500-1000 units
추가적으로, hidden layer는 vocabulary 속 모든 단어들에 대한 확률 분포 계산에 사용되며, 이는 output layer로 들어가 V 차원의 벡터 출력
-
계산 복잡도
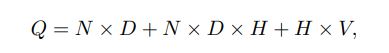
HxV가 연산량의 큰 부분을 차지하지만, 이런 문제를 해결하기 위해 hierarchical 버전의 softmax를 사용하거나 학습 시에 정규화되지 않은 모델을 사용하여 정규화를 피하는 방식 등 해결책이 제안됨
vocabulary의 이진 트리 표현과 함께, output units의 수가 약 log2(V)로 감소함
이제 대부분의 연산량은 NxDxH가 차지
-
해당 논문의 모델은 vocabulary를 허프만 이진 트리로 표현하는 hierarchical softmax를 사용함
허프만 트리는 자주 등장하는 단어들에 짧은 이진 코드를 할당하고, 이는 평가되어야 할 output units의 수를 줄임
허프만 트리는 balanced 이전 트리와 비교하였을 때, 백만개의 vocabulary 사이즈를 가질 때, evaluation 타임에 2배 가까이 빠르지만, 비중이 큰 term은 NxDxH이기 때문에 이를 해결하지 못함
논문에서는 이를 해결하기 위해, hidden layers를 없애서 softmax normalization의 효율에 집중한 모델을 제안
Recurrent Neural Net Language Model (RNNLM)
-
RNN은 feedforward NNLM의 특정 한계를 극복하기 위해 제안됨
context length(순서 고려)를 구체화하기 위해 필요
이론적으로 RNN은 얕은 neural networks 보다 복잡한 패턴들을 효율적으로 표현할 수 있음
-
RNN 모델은 projection layer를 가지지 않고, 모직 input, hidden, output layer만을 가짐
RNN의 특이한 점은 hidden layer가 시간 차이로 자기 자신한테 다시 연결된다는 점 (t-1 hidden vector가 t 시점 입력으로 들어옴)
이는 recurrent model이 short term memory를 생성하게 함
-
계산 복잡도
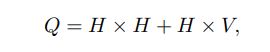
word representations D는 hidden layer H와 동일한 차원을 가지며, 여기서 HxV를 hierarchical softmax를 사용하여 Hxlog2(V)로 감소시킬 수 있음
결과적으로, 대부분의 연산은 HxH가 차지
Parallel Training of Neural Networks
- 대규모 데이터셋으로 학습시키기 위해, DistBelief라고 불리는 large-scale distributed framework 위에 여러 개의 모델을 구현함
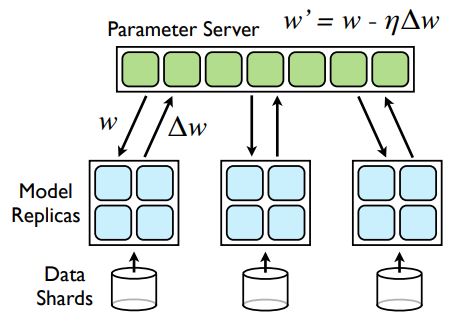
이 framework는 동일한 모델의 다양한 복제본을 병렬적으로 실행시키는 것을 가능하게 하고, 각 복제품은 한개의 중앙 서버(모든 파라티머 관리)를 통해 gradient가 업데이트 됨
병렬 학습을 위해, adaptive learning rate를 적용시킨 mini-batch asynchronous gradient descent를 사용(Adagrad)
New Log-linear Models
-
논문에서는 단어의 분산 표현을 학습하기 위한 새로운 두가지 모델을 제안
계산 복잡도를 최소화하는 것에 초점을 맞춤
-
연산을 복잡하게 하는 것은 non-linear hidden layer가 원인이고, 이것이 neural network가 잘 동작하는 이유이지만, 단순한 모델을 연구하는데 집중함
neural network만큼 정확하지 않겠지만, 단순한 모델은 대규모 데이터셋에서 효율적으로 학습시키는 것이 가능함
-
논문이 제시하는 모델의 구조들은 이전에 two-step 방식으로 학습하는 neural network language model에서 아이디어를 얻음
1) 단순한 모델을 이용하여 연속적인 단어 벡터들을 학습
2) 단어들의 분산 표현을 이용하여 N-gram NNLM 학습
Continuous Bag-of Words Model
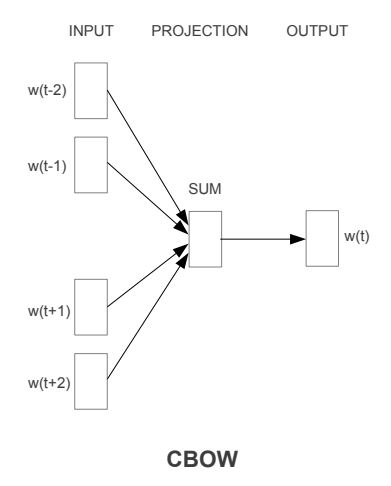
-
제안된 구조는 feedforward NNLM과 유사함
non-linear hidden layr가 제거되었고, projection layr가 모든 단어들에게 공유됨
모든 단어들이 같은 위치에 projection 됨 (모든 단어들의 벡터를 평균냄)
-
단어들의 순서가 projection에 영향을 미치지 않기 때문에, 해당 구조를 bag-of-words model이라고 부름
-
뒤에 나오는 단어들을 학습에 사용함
다음 섹션에서 4개의 이전 단어들과 4개의 이후 단어들을 입력으로 받아 중간 단어를 예측하는 log-linear classifier를 만들어 최고 성능을 얻음
-
학습 복잡도
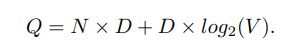
-
해당 모델이 연속적인 분산 표현을 사용하기 때문에 CBOW 라고 표기함
input layer와 projection layer 사이 weight matrix가 모든 단어 위치에서 공유됨
Continuous Skip-gram Model
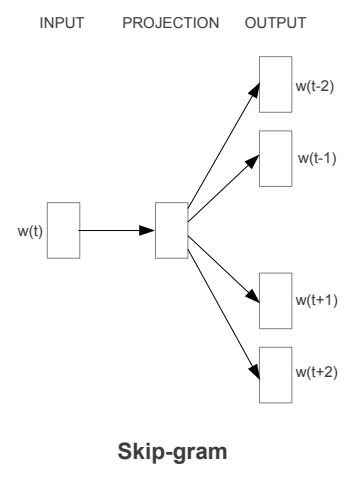
-
CBOW와 달리, 문맥을 고려하여 현재 단어를 예측하는 모델
동일한 문장 내에서 다른 단어들을 기반으로 하나의 단어 분류를 극대화시키기 위해 노력
-
더 정확하게, 연속적인 projection layer를 가진 log-linear classifier의 입력으로 현재 단어를 넣고, 특정 범위 내 단어들(현재 단어 기준 이전 단어들과 이후 단어들)을 예측하게 함
-
범위가 커질수록 단어벡터들의 결과가 좋았지만, 계산 복잡도 또한 증가함
-
거리가 먼 단어들은 서로 적은 연관성을 가지기 때문에, 학습 샘플에서 적게 샘플링하여 더 적은 weight를 줌
-
학습 복잡도
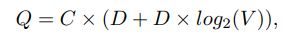
C : 단어들 사이의 최대 거리
C = 5 이면, <1;C> 범위에서 랜덤으로 R개 학습 단어들 샘플링
input : 과거 단어 R개, 미래 단어 R개를 정답 라벨로 사용
현재 단어를 입력으로 받아, 총 Rx2 개 단어의 분류가 필요 (과거 R, 미래 R)
실험에서는 C = 10 사용
Leave a comment