
[Paper Review] Enriching word vectors with subword information
Enriching word vectors with subword information
Bojanowski, Piotr, et al. “Enriching word vectors with subword information.” Transactions of the association for computational linguistics 5 (2017): 135-146.
Abstract
라벨링 되지 않은 대규모 데이터로 학습된 연속 단어 표현은 많은 자연어처리 task에서 유용함
이런 벡터 표현을 학습하는 유명한 모델들은 각 단어에 고유한 벡터를 할당함으로써 단어들의 형태를 무시하는 문제점이 있음
이러한 문제점은 대규모 단어들과 많은 희귀한 단어들이 포함된 언어에서 도드라짐
-
Skip-gram model을 기반으로 한 새로운 접근법 제안
각 단어들은 character n-grams의 집합으로 표현됨
하나의 벡터는 각 character n-gram과 연관이 있고, 단어는 이러한 representations의 합으로 표현됨
-
논문에서 제안한 접근법은 빠르고, 학습 데이터에서 등장하지 않은 단어에 대해서도 word representation 수행이 가능함
9개 언어에서 word similarity, analogy tasks에서 word representations을 평가
최근 제안된 morphological word representations 방식들과 비교하였을 때, SOTA 성능을 보임
Introduction
자연어처리 분야에서 연속 벡터 표현을 학습시키는 것은 오랜 역사를 가지고 있음
이러한 표현은 일반적으로 동시 발생 통계를 사용하여 라벨링 되지 않은 대규모 데이터셋에서 파생됨
distributional semantics이라고 알려진 연구 분야에서 이러한 방법의 특성을 연구함
분포 의미론(Distributional Semantics)은 언어 데이터의 큰 샘플에서 분포 속성을 기반으로 언어 항목 간의 의미론적 유사성을 정량화하고 분류하기 위한 이론과 방법을 개발하고 연구하는 연구 분야
분포 의미론의 기본 아이디어는 소위 분포 가설로 요약될 수 있습니다.
유사한 분포를 가진 언어 항목은 유사한 의미를 갖습니다.
https://en.wikipedia.org/wiki/Distributional_semantics
Collobert와 Weston은 왼쪽 단어 2개, 오른쪽 단어 2개를 통해 하나의 단어를 예측하는 feed-forward neural network를 사용하여 word embeddings을 학습하는 방식을 제안
가장 최근에는 Mikolov가 대규모 데이터셋에서 연속 word representations을 효율적으로 학습하기 위한 단순한 log-bilinear models 제안 (Word2Vec)
이러한 기법들의 대부분은 vocabulary 속 각 단어를 파라미터 공유없이 하나의 특정 벡터로 나타냄
이런 방법들은 단어들의 내부 구조를 무시하고, 이는 Turkish, Finnish와 같이 형태론적으로 풍부한 언어에서 정확한 표현을 어렵게 함
프랑스어나 스페인어에서 대부분의 동사는 40가지 이상의 다른 굴절 형태를 가지만, 핀란드어에서는 명사에 대해 15가지 경우가 있음
이런 언어들은 학습 데이터에서 전혀 등장하지 않거나 드물게 등장하는 단어 형태를 많이 포함하고 있고, 이는 word representations 학습을 어렵게 만듦
많은 단어 구성이 규칙을 따르기 때문에, 문자 수준 정보를 사용하면 형태학적으로 풍부한 언어에 대한 벡터 표현을 개선할 수 있음
-
character n-grams에 대해 벡터 표현을 학습하고, n-gram 벡터들의 합으로 각 단어를 표현하는 방식을 제안
-
연속적인 skip-gram model을 확장시킨 방식이고, subword 정보를 고려할 수 있도록 함
해당 모델의 강점을 증명하기 위해, 다른 형태적 요소가 존재하는 9개의 언어에서 성능을 평가함
Related work
Morphological word representations
최근, 형태소 정보를 word representations에 통합하기 위한 많은 방식들이 제안됨
자주 등장하지 않는 단어(rare words)들을 잘 다루기 위해, Alexandrescu와 Kirchhoff는 factored neural language model을 도입
단어들을 형태소 정보를 포함하는 features의 집합으로 표현
이런 기법을 TurKish와 같이 형태학적으로 풍부한 언어 표현을 가진 언어에서 성공적으로 동작함
이러한 다양한 접근법은 단어의 형태학적 분해에 의존하지만 논문에서 제안한 접근법은 그렇지 않음
-
다양한 접근법
-
중국어에서 단어들과 문자들에 대한 임베딩을 함께 학습시키는 방식
-
형태학적으로 비슷한 단어들이 비슷한 representations을 갖도록 제한시키는 방식
-
형태소 정보의 representations을 학습시켜 학습 데이터로 보지 못한 단어의 representaiton을 얻을 수 있도록 한 방식
-
특이값 분해를 통해 문자 4-gram의 표현을 학습하고, 4-gram 표현을 합산하여 단어에 대한 표현을 얻어냄 (논문의 접근법과 가장 유사)
-
문자 단위 n-gram count vectors를 사용하여 단어를 표현하는 방식
-
-
이러한 paraphrase pairs 기반 표현 방식들에서 사용되는 objective function은 어떤 text corpus에서도 학습시킬 수 있는 논문의 모델과 차이가 있음
Character level features for NLP
논문의 접근법과 유사한 연구는 자연어처리를 위해 문자 단위 정보를 활용하는 모델
이러한 모델은 단어로의 분할을 버리고, 문자에서 직접 언어 표현을 학습하는 것을 목표로 함
-
recurrent neural networks
-
문자 단위로 학습시킨 convolutional neural networks
-
단어가 문자 n-gram의 집합으로 인코딩되는 restricted Boltzmann machines를 기반으로 하는 언어 모델
https://www.asimovinstitute.org/neural-network-zoo/
- 기계 번역의 최근 연구에서 subword unit을 사용하여 희귀 단어의 표현을 얻을 것을 제안
Model
-
단어의 형태를 고려하여 단어 표현을 학습하는 모델을 제안
-
제안된 모델은 subword units을 고려하고, 문자 단위 n-grams의 합으로 단어를 표현하여 형태를 모델링
General model
- Continuous skip-gram model
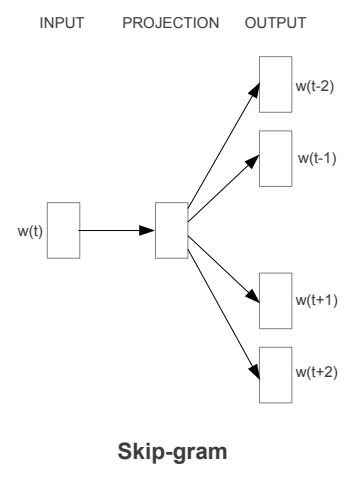
Word2Vec에서 제안된 모델
vocabulary size W가 주어지면, 각 단어는 index \(w \in {1,...,W}\)로 맵핑되고, 여기서 각 단어 w에 대한 벡터 표현을 학습하는 것을 목표로 동작
분포 가설에서 영감을 얻어서 문맥에 등장하는 단어들을 예측하기 위해 학습됨
제안된 방식에서는 scoring function s가 주어짐
단어와 문맥의 쌍들을 scores로 맵핑
하나의 context word에 대한 확률을 정의하기 위한 방식에는 softmax가 있음
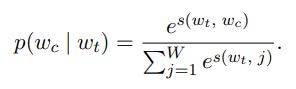
하지만 이 방법은 하나의 단어가 주어졌을 때, 오직 하나의 context word를 예측한다고 가정이 되어있기 때문에 우리의 방식에 적용할 수 없음
context words 예측 문제는 독립적인 이진 분류 문제들의 집합으로 생각할 수 있고, 이런 방식은 context words의 존재 또는 부재를 독립적으로 예측할 수 있음
t 위치에 해당하는 단어에 대해 랜덤으로 모든 context words를 positive examples과 sample negatives로 고려할 수 있음
선택된 context position c에 대해, binary logistic loss를 사용하여 negative log-likelihood를 얻을 수 있음
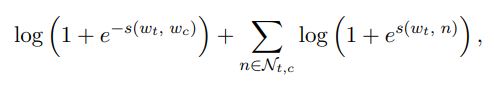
주변 단어에 대한 loss + negative sample에 대한 loss
\(N_{t,c}\) : vocabulary에서 샘플링된 negative examples의 집합
word wt와 context word wc 사이 Scoring function s에 대한 자연적인 매개변수화는 단어 벡터들을 사용하는 것
단어 wt와 context word wc의 벡터들 간의 곱으로 score를 얻을 수 있음 (전치행렬x행렬)
Subword model
각 단어에 대해 하나의 고유한 벡터로 표현함으로써, skipgram model은 단어들의 내부적 구조를 무시함
- 논문에서 단어의 내부 구조를 고려하기 위해 scoring function s 제안
각 단어 w는 character n-gram의 집합으로 표현됨
접두사와 접미사를 다른 문자 시퀀스와 구별하기 위해, 특수 심볼 추가 (‘<’:단어의 시작, ‘>’:단어의 끝)
각 단어 벡터 표현을 학습하기 위해, n-grams 집합에 단어 w 자체도 포함시킴
- character n-grams 예시
where, n=3
<wh, whe, her, ere, re>
여기에 원래 단어인 <where> 도 포함
n-grams에서 n은 3-6 사이의 값을 사용함
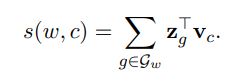
간단한 모델을 통해 단어 간에 표현을 공유할 수 있으므로 희귀 단어에 대한 신뢰할 수 있는 표현을 학습
메모리 요구 사항을 제한하기 위해 n-gram을 1에서 K의 정수로 매핑하는 해싱 기능을 사용
Fowler-Noll-Vo 해싱 기능(특히 FNV-1a 변형)을 사용하여 문자 시퀀스를 해싱
궁극적으로 단어는 단어 사전의 색인과 포함된 해시된 n-gram 집합으로 표현
Leave a comment