
[Paper Review] Character region awareness for text detection
Character region awareness for text detection
Baek, Youngmin, et al. “Character region awareness for text detection.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019.
Abstract
최근 neural networks 기반 scene text detection 방식들이 등장하였고, 좋은 성능을 보임
word-level bounding box로 학습된 기존의 방식들은 임의로 모양을 가진 텍스트의 영역을 표현하는데 제한적임
단어 단위로 학습된 방식들은 굴곡이 있거나 일반적이지 않은 모양의 텍스트를 나타내기에 적합하지 않음
본 논문에서는 개별적인 글자와 글자들 사이 affinity(관련성)를 탐색하여 텍스트 영역을 효과적으로 검출할 수 있는 새로운 text detection 방식 제안함
글자 단위 annotations이 부족한 것을 해결하기 위해, 가상의 데이터셋에서 주어진 글자 단위의 annotations과 실제 데이터셋으로부터 예측된 글자 단위 ground-truths를 함께 활용함
글자들 사이 affinity를 추정하기 위해, 네트워크가 affinity를 위해 새롭게 제안된 representation과 함께 학습됨
-
실험 결과
매우 굴곡진 텍스트를 포함하고 있는 TotalText, CTW-1500 등 총 6개의 벤치마크에서 큰 격차로 SOTA 달성
제안한 방식은 임의의 방향, 굴곡, 변형된 텍스트와 같이 복잡한 scene text images를 잘 탐지하는데 높은 유연성을 보장함
Introduction
Scene text detection은 많은 응용분야로 인해 컴퓨터 비전 분야에서 많은 관심을 받았음
instance translation, image retrieval, scene parsing, geo-location, blind-navigation
최근, 딥러닝 기반 scene text detectors는 좋은 성능을 보임
딥러닝 기반 방식들은 주로 단어 단위(word-level) 바운딩 박스를 localization 하기 위해 학습되지만, 이는 단일 바운딩 박스로 예측하기 어려운 모양(curved, deformed)의 텍스트를 예측하는데 어려움을 겪음
대안으로 challenging texts를 다룰 때, 글자 단위(character-level) 인식이 큰 이점을 얻을 수 있음
글자 단위로 탐지하고, 연속적인 글자들을 연결하는 상향식 방법
하지만, 존재하는 대부분의 데이터셋은 글자 단위 annotations을 제공하지 않고, 글자 단위 ground truths를 얻는 것은 매우 비용이 많이 듦
개별적인 글자들의 영역을 탐지하고, 탐지된 글자들을 text instance로 연결하는 새로운 text detector 제안
-
CRAFT (Character Region Awareness For Text detection)
글자에 대한 region score와 affinity score를 생성하는 convolutional neural network
-
region score : 이미지 속 개별적인 글자들을 localization
-
affinity score : 각 글자를 하나의 instance로 그룹화하기 위해 사용되는 score
글자 단위 annotations이 부족한 것을 보완하기 위해, 존재하는 실제 word-level 데이터셋에서 character-level ground truths를 예측하는 weakly supervised learning framework 제안
-
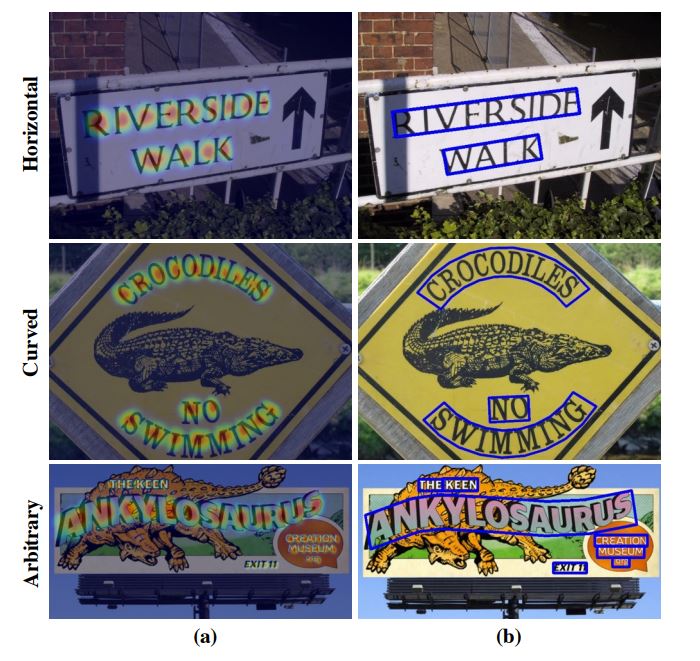
글자 단위로 텍스트 영역을 인식하여 다양한 모양을 가진 텍스트를 쉽게 나타낼 수 있음
ICDAR 데이터셋에 대해 광범위한 실험을 통해 제안한 모델을 평가하였고, SOTA를 뛰어넘는 성능을 보임
또한, MSRATD500, CTW-1500, TotalText 데이터셋에 대한 실험에서 복잡한 경우(long, curved, arbitrarily shaped texts)에 대한 높은 유연성을 보임
Related Work
딥러닝이 등장하기 이전에 scene text detection의 주요 트렌드는 MSER, SWT와 같이 hand-crafted features를 사용하는 bottom-up 방식이었음
최근에는 SSD, Faster R-CNN, FCN과 같이 object detection/segmentation에 사용하는 방식들을 적용시킨 딥러닝 기반 text detector가 제안됨
[Regression-based text detectors]
널리 사용되는 object detectors에서 채택한 box regression을 사용하는 다양한 text detectors가 제안됨
텍스트는 일반적으로 objects와 달리 다양한 종횡비로 불규칙한 모양인 경우가 많음
-
불규칙한 모양의 텍스트를 다루기 위한 다양한 시도들
TextBoxes : 다양한 텍스트 모양를 효과적으로 탐지하기 위해 convolutional kernels과 anchor boxes를 수정
DMPNet : 사변형 슬라이딩 창(quadrilateral sliding windows)을 통합하여 문제를 줄이려고 노력함
RSDD : convolutional filters를 동적으로 회전시켜 회전 불변 특성(rotation-invariant features)을 최대한 활용함
-> 하지만, 실제 세계에 존재하는 가능한 모양을 탐지하기에는 구조적 제한이 있음
[Segmentation-based text detectors]
또 다른 접근법은 픽셀 단위로 text regions을 찾는 segmentation 방식
word 단위 영역을 예측하여 텍스트를 탐지하는 Multi-scale FCN, Holistic-prediction, PixelLink
SSTD는 feature level에서 배경의 방해를 줄이고 텍스트 관련 영역을 향상시키기 위한 attention mechanism 사용하여 regression과 segmentation 방식의 이점을 모두 얻으려 함
TextSnake geometry attributes와 함께 텍스트 영역과 center line을 예측하여 text instances를 탐지하는 방식을 제안
[End-to-end text detectors]
text detection과 text recognition을 동시에 학습시키는 end-to-end 방식이고, recognition 정확도를 높이기 위해 학습하는 과정에서 detection 정확도를 향상시키게 됨
FOTS와 EAA는 많이 사용되는 detection과 recognition 방식들을 이어 붙여서 end-to-end 방식으로 학습시킴
Mask TextSpotter는 semantic segmentation 문제로 recognition task를 해결하기 위해 통합된 모델을 사용하여 이점을 얻음
-> recognition 모듈을 함께 학습하는 것이 text detector를 더욱 강력하게 만드는데 도움이 되는 것은 분명함
대부분의 방식들은 텍스트를 단어 단위로 탐지하지만, 탐지를 위한 단어를 어떤 범위(meaning, spaces, color)에서 정의해야 하는지도 중요한 문제임
게다가 word segmentation의 범위가 정확히 단어만을 포함하지 않고 배경 정보도 함께 포함하고 있기 때문에 word segmentation 그자체는 특정한 의미담고 있지 않음
word annotation에서 이러한 애매모호함은 regression과 segmentation 접근법 모두에서 ground truth의 의미를 희석한다는 문제가 생김
[Character-level text detectors]
Zhang et al는 MSER에 의한 text block candidates를 사용한 character level detector 제안
개별적인 글자를 탐지하기 위해 MSER을 사용하는 것은 특정 상황(low contrast, curvature, light reflection)에서의 detection 성능을 제한시킴
Yao et al은 text word regions, linking orientations map과 함께 characters prediction map을 예측
character level annotations을 필요로 함
Seglink는 명확히 글자 단위로 나누는 예측하는 방식 대신 텍스트 그리드(부분적인 텍스트)를 찾고, 추가적인 link prediction과 함께 segments를 연결시키는 방식을 제안
Mask TextSpotter는 글자 단위 probaility map을 예측하여 text recognition에 활용함
본 논문은 글자 단위 detector를 학습시키기 위해 weakly supervised framework를 사용한 WordSup에서 아이디어를 얻음
하지만, Wordsup은 직사각형의 anchors로 글자를 표현하면서 다양한 카메라 각도에서 촬영된 글자의 변형에 대해 취약하다는 단점이 있고, anchor boxes의 수와 사이즈가 제한적인 SSD를 backbone으로 이용하여 성능이 제한됨
Methodology
자연적인 이미지 속 개별적인 글자들을 정확하게 localization 하는 것이 목적
character regions과 글자들 사이 affinity를 예측하기 위해 네트워크가 학습됨
이용할 수 있는 단어 단위의 데이터셋이 없기 때문에 weakly supervised 방식으로 모델을 학습시킴
Architecture
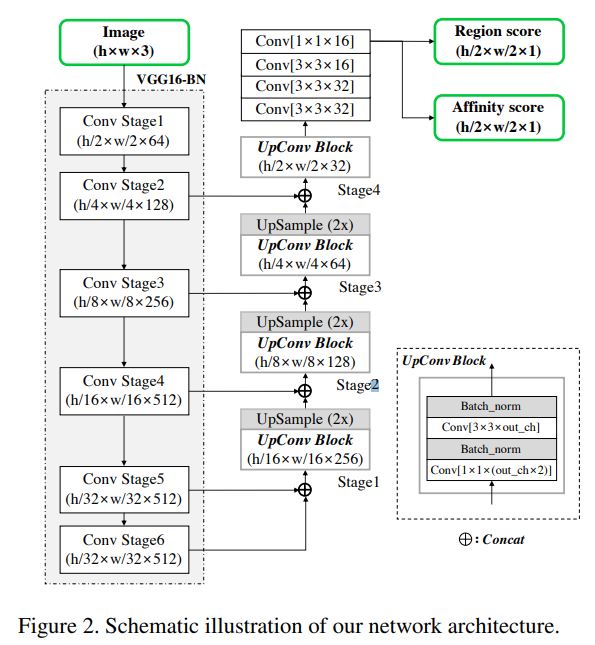
batch normalization이 적용된 VGG-16 기반 fully convolutional network를 backbone으로 사용
디코딩 하는 과정에서 U-net과 유사하게 low-level feature를 융합시키는 skip connections을 사용
네크워크의 최종적인 출력은 score maps을 위한 2개의 채널(region score, affinity score)을 가짐
Training
Ground Truth Label Generation
각 학습 이미지에 대해 region score, affinity score에 대한 ground truth label과 함께 character-level bounding boxes 생성
region score : 주어진 픽셀이 character의 중심인지에 대한 확률을 나타냄
affinity score : 인접한 글자들 사이의 공백의 중심인지에 대한 확률을 나타냄
각 픽셀에 대해 분별적으로 라벨링되는 binary segmentation map과 달리, 가우시안 히트맵으로 글자 중심 확률을 인코딩함
이 히트맵 표현은 엄격하게 제한되지 않은 실측 영역을 처리할 때 높은 유연성으로 인해 포즈 추정 작업[1, 29]과 같은 다른 응용 프로그램에서 사용되었습니다.
heatmap representation은 높은 유연성으로 인해 pose estimation과 같이 엄격하게 제한되지 않은 ground truth regions을 다루는 분야에서 사용됨
논문에서는 region score와 affinity score를 학습시키기 위해 heatmap representation을 사용
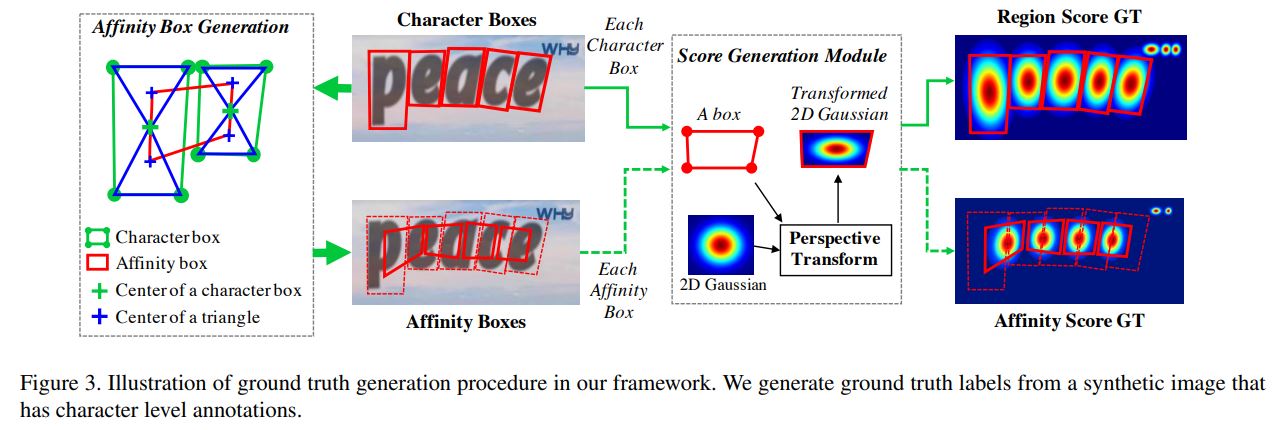
가상의 데이터셋에서 label을 생성하는 파이프라인
바운딩 박스 내 모든 픽셀에 대해 가우시안 분포를 계산하는 것은 매우 많은 시간이 소모됨
이미지 속 글자 바운딩 박스는 perspective projections을 통해 왜곡되기 때문에 다음과 같은 과정을 수행함
-
score map 생성 과정
-
2차원 isotropic Qaussian map 준비
-
가우시안 맵 영역과 글자 바운딩 박스 영역 사이의 perspective transform 계산
-
가우시안 맵을 박스 영역으로 warping
-
-
affinity score 생성 과정
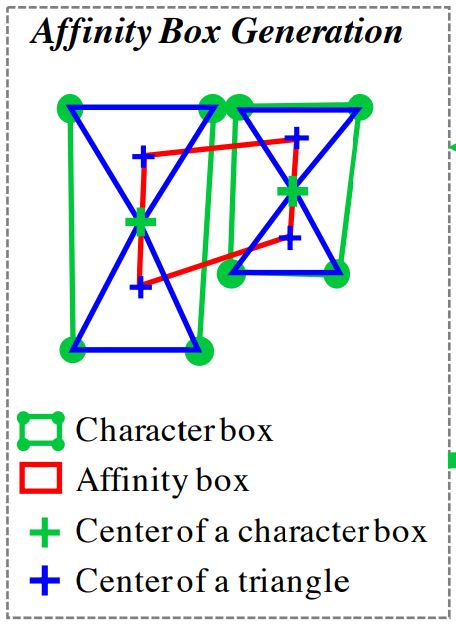
affinity boxes는 인접한 글자의 박스를 이용하여 정의됨
인접한 글자 상자에서 대각선을 모두 그리고, 대각선으로 인해 생긴 위, 아래 삼각형 센터를 인접 글자 상자의 위, 아래 삼각형 센터에 각각 연결시켜서 박스 생성
제안된 ground truth definition은 작은 receptive fields를 사용함에도 불구하고, 모델이 크거나 긴 텍스트를 잘 탐지할 수 있도록 도와줌
기존의 box regression과 같은 접근법들은 큰 receptive field를 필요로 함
논문에서 제안한 character-level detection은 convolutional filters가 전체 텍스트 대신 글자 내 글자 간 관계에만 집중할 수 있도록 함
Weakly-Supervised Learning
가상의 데이터셋과 달리, 실제 데이터셋은 일반적으로 단어 단위 annotations을 포함하고 있음
본 논문에서는 weakly-supervised 방식으로 word-level annotation에서 character boxes를 생성함
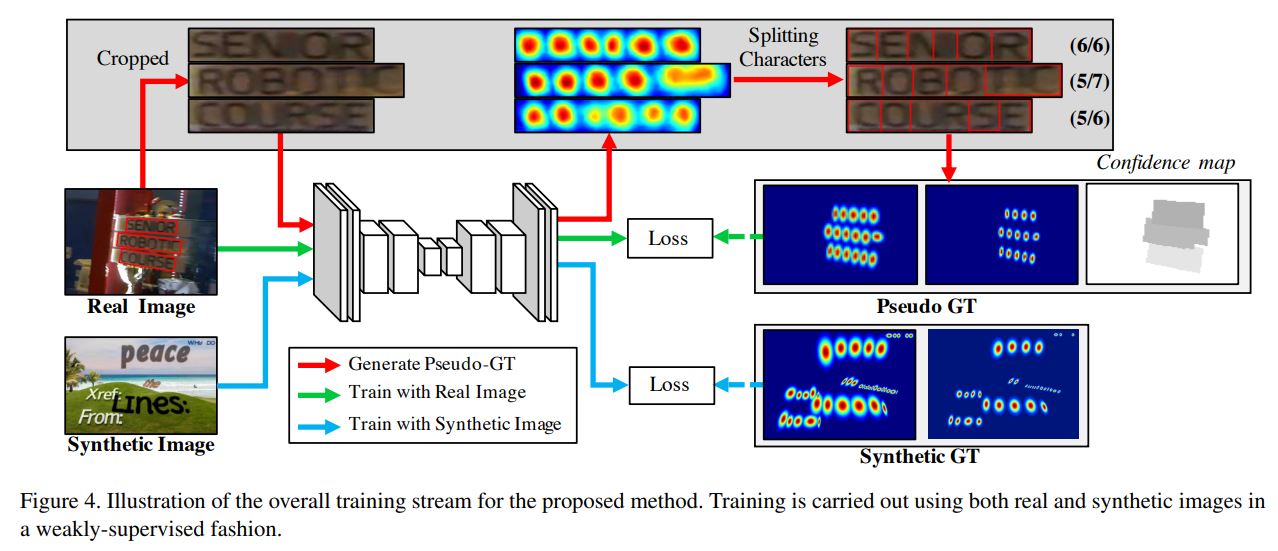
word-level annotations을 가진 실제 이미지가 주어졌을 때, 글자 단위 바운딩 박스를 생성하기 위해 중간 모델은 크롭된 글자 이미지로부터 character region score를 예측함
중간 모델의 예측값의 신뢰도를 반영하기 위해, 각 단어 상자에 대한 confidence map의 값이 계산됨
감지된 문자의 수를 정답 문자의 수로 나눈 값에 비례하여 계산 (글자수가 동일해야 정확히 예측한 것)
-
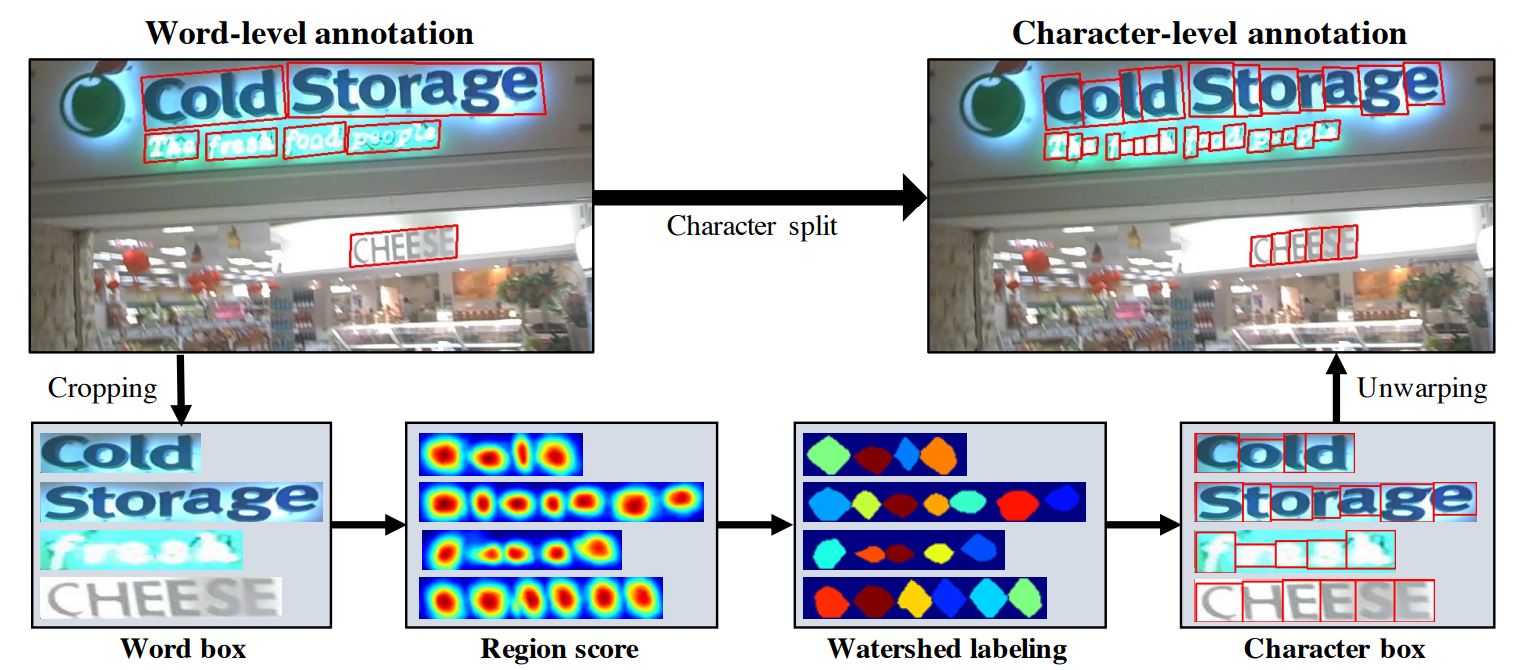
word-level annotation에서 character-level annotation을 생성하는 과정
-
원본 이미지에서 단어가 있는 영역을 크롭
-
이미지가 모델을 통과하여 region score를 예측
-
watershed 알고리즘을 이용하여 글자 영역을 분리
-
글자 박스의 coordinates를 원본 이미지 coordinates로 변형하여 적용시킴 (크롭하는 것을 반대로 수행하는 과정)
-
weak-supervision을 통해 모델이 학습될 때 불완전한 pseudo-GTs와 함께 학습이 되고, 만약 부정확한 region scores로 학습된다면 출력 또한 블러리한 결과로 나오게 됨
이런 문제를 보완하기 위해, 모델에 의해 생성된 pseudo-GTs의 질을 단어에 속한 글자의 수를 이용하여 평가함
대부분의 데이터셋에서 word length를 제공하고, 이를 활용하여 pseudo-GTs의 신뢰성을 평가할 수 있음
-
word-level annotated sample w에 대한 confidence score $s_{conf}(w)$
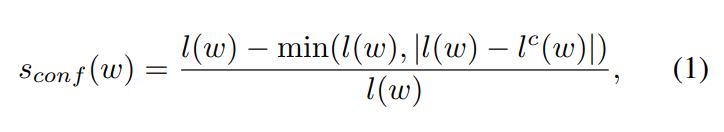
$l(w)$ : word length of the sample w
$l^c(w)$ : 예측된 character bounding boxes의 개수
-
이미지에 대한 픽셀 단위 confidence map $S^c$
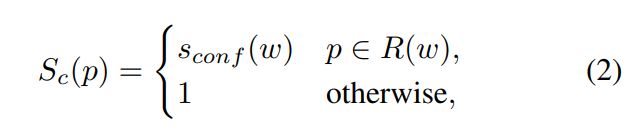
$R(w)$ : bounding box region of the sample w
-
Loss function
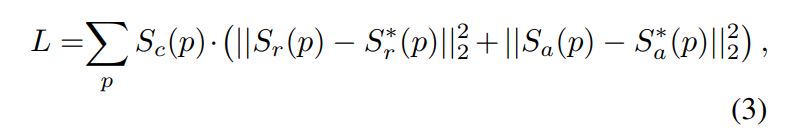
region score와 affinity score의 pseudo GT와 예측된 값 사이의 loss값을 confidence score를 고려하여 계산
가상의 데이터셋의 경우 글자 단위 라벨값이 존재하므로 신뢰도를 모두 1로 설정하고 학습
만약 confidence score가 0.5 보다 낮다면, 오히려 학습을 방해할 수 있기 때문에 학습에 반영하지 않음
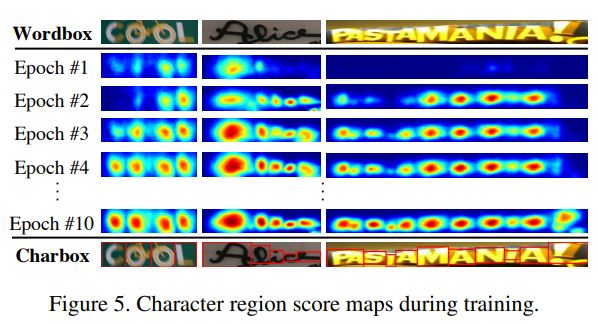
모델이 학습을 어려번 거치면서 더 정확하게 글자들을 예측하고, confidence scores 값도 점차 증가함
Leave a comment