
[Paper Review] Transferable multi-domain state generator for task-oriented dialogue systems
Transferable multi-domain state generator for task-oriented dialogue systems
Wu, Chien-Sheng, et al. “Transferable multi-domain state generator for task-oriented dialogue systems.” arXiv preprint arXiv:1905.08743 (2019).
Abstract
domain ontology에 과의존하는 것과 domains 사이 지식 공유의 부족은 중요한 문제이지만 연구로 많이 다루어지지 않았음
domain ontology : 예측하고자 하는 도메인들을 미리 정의해두고, 정해진 도메인만을 예측할 수 있는 방식
-
기존 방식의 한계점
-
inference 시 학습 데이터로 보지 못한 slot이 들어오게 되면 tracking 할 수 없음
-
새로운 domains으로 적용시키기 어려움
-
본 논문에서는 TRAnsferable Dialogue statE generator (TRADE) 제안
TRADE는 copy mechanism을 이용하여 발화(utterances)에서 dialogue states를 생성하고, 학습 데이터로 보지 못한 (domain, slot, value) triplets을 예측할 때 지식 전이를 용이하게 함
TRADE는 domains 간 정보를 공유하는 3가지 모듈로 구성되어 있음
-
an utterance encoder
-
a slot gate
-
a state generator
-
실험 결과
-
human-human dialogue dataset인 MultiWOZ의 5개 domains에서 joint goal accuracy 48.62%로 SOTA 달성
-
보지 못한 domains에 대한 zero-shot, few-shot dialogue state tracking에서 transferring ability를 보여줌
-
Introduction
Dialogue state tracking (DST)는 식당 예약, 티켓 예매와 같은 task-oriented dialogue systems에서 핵심적인 요소임
-
DST의 목적
사용자의 대화 속에서 목적/의도를 추출하고, 그것을 dialogue states의 집합 형태로 인코딩하는 것
예를 들어, (slot, value) 형태로 표현한다면, 대화에서 (price, cheap), (area, centre)와 같은 정보를 추출해내는 것
-> 사용자의 의도가 데이터베이스에서 검색할 내용이나 시스템의 다음 action을 결정하기 때문에 대화 관리에서 DST의 성능은 매우 중요함
전통적인 state tracking 접근법들은 사전에 ontology가 정의되어 있음을 가정함
모든 slots과 그에 따른 values를 모두 알고 있다는 가정의 접근법
이러한 접근법은 DST 문제를 간소화시켜 classification 문제로 해결할 수 있게 하였고, 이는 많은 성능 향상을 가져옴
하지만, 이런 접근법은 치명적인 2개의 결점이 존재함
-
사전에 모든 ontology를 얻는 것은 매우 어려움
-
모든 ontology를 얻을 수 있다고 가정하더라도 가능한 slot values의 수가 너무 많고, 변화가 가능함
위와 같은 문제점으로 인해 classification 기반 방식은 실제로 활용되기에는 어려움이 있음
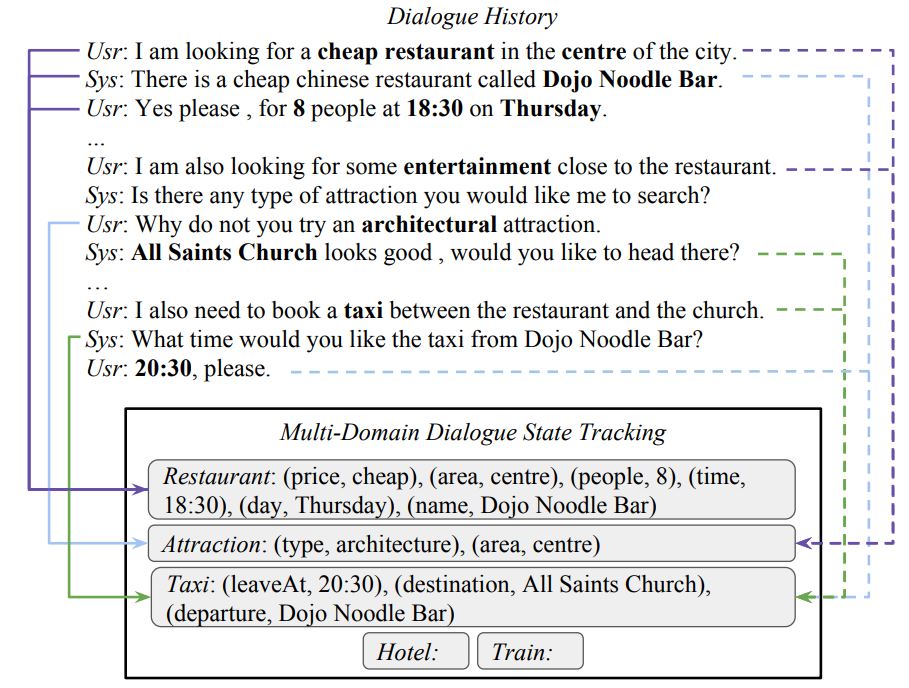
최근 multi-domain dialogue dataset (Multi-WOZ)이 새롭게 도입되면서 다양한 domains이 섞인 대화에서의 DST인 새로운 challenges가 추가됨
위 그림(fig 1)의 대화 흐름
식당 예약 질문 -> 근처 관광명소 질문 -> 택시 예약 요청
이런 경우, DST 모델은 각 dialogue의 turn에 해당하는 domain, slot, value를 결정해야 하고, 이는 30개의 (domain, slot) 쌍과 약 4,500개의 가능한 slot values를 포함
multi-damain setting의 또다른 challenge는 multi-turn mapping을 수행하는 것
single-turn에서 (domain, slot, value)를 추론하는 single-turn mapping과 달리 다양한 domains에서 발생한 multiple turns에서 추론해야 함
예를 들어, 그림 속 attraction domain에서 추론된 (area, centre) 정보는 이전 turns에서 언급된 restaurant domain의 area를 참고하여 추론된 정보
-
이러한 challenges를 다루기 위해, 논문에서는 DST 모델이 domains 간 tracking knowlegde를 공유해야 함을 강조함
restaurant, attraction, taxi domain 모두 area slot을 가지고 있고, restaurant의 name slot과 taxi의 departure slot의 value는 동일할 수 있기 때문에 도메인 사이 많은 slot들은 정보 공유를 하고 있고, 이를 적절히 활용할 수 있어야 함 -
보지 못한 domains에서도 slots을 추적하기 위해, 다양한 도메인간 지식 전이는 필수적임
the main advantage of TRADE
-
multi-turn mapping 문제를 해결하기 위해, TRADE는 대화 기록 어느 곳에서 언급된 slot 값이라도 적절하게 추적하기 위해 context-enhanced slot gate, copy mechanism 활용
-
TRADE는 보지 못한 slot values 추적을 위해 도메인 간 지식을 공유(미리 정의된 ontology 없이 도메인 간 파라미터 공유)하였고, multi-domain DST에서 SOTA 달성
-
zero-shot DST를 가능하게 함
TRADE Model
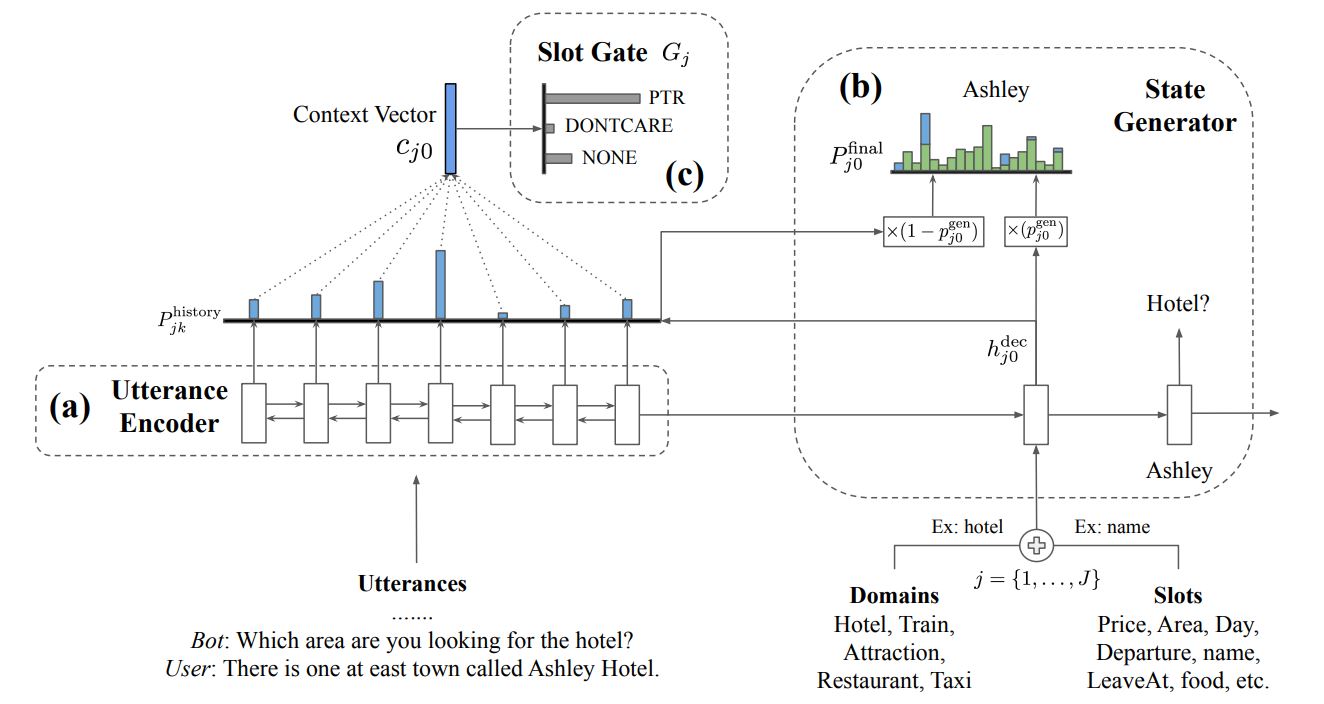
TRADE는 utterance encoder, slot gate, state generator 이렇게 총 3가지 구성요소로 이루어짐
기존에 정의된 모든 ontology term의 확률을 예측하는 방식이 아닌 직접 slot values를 생성하는 방식
모델의 모든 파라미터를 공유하고, state generator가 (domain, slot) pair 별로 다른 start-of-sentence token과 함께 시작
Utterance encoder는 dialogue utterances를 고정된 길이의 벡터 시퀀스로 인코딩
(domain, slot) 쌍이 언급되었는지를 결정하기 위해, state generator와 함께 context-enhanced slot gate가 사용됨
state generator는 모든 (domain, slot)에 대해 관련있는 values를 예측하기 위해 다양한 output tokens을 디코딩
context-enhanced slot gate는 three-way classifier를 통해 각각의 쌍이 실제로 대화에서 등장하는지 예측
Utterance Encoder
utterance encoder는 기존에 존재하는 모든 인코더로 대체가 가능하고, 논문에서는 bi-directional gated recurrent units (GRU)를 사용
encoder input : dialogue history의 모든 단어들의 concatenation
현재 시점 기준 과거의 l개의 dialouge turns 정보를 embedding size $d_{emb}$로 표현
인코딩된 dialogue history는 $H_{t}$로 표현됨
multi-turn mappping 문제를 해결하기 위해, 모델은 turns의 시퀀스 정보를 활용하여 states를 추론함
multi-turn mapping을 위해 현재 utterance 만으로 예측하지 않고, 과거의 l개의 dialogue 정보를 사용
State Generator
input source의 텍스트를 이용하여 slot values를 생성하기 위해서는 copy mechanism이 필요
일반적으로 사용되는 copy mechanism에는 index-based copy, hard-gated copy, soft-gated copy 3가지가 있음
하지만, utterance에서 slot value와 정확히 일치해야만 단어를 찾을 수 있는 방식인 index-based mechanism과 gating function에 대한 추가적인 학습을 필요로 하는 hard-gate copy mechanism은 적절하지 않다고 판단하여 논문에서는 soft-gated copy 방식을 선택
-> vocabulary에 대한 분포와 dialogue history에 대한 분포를 하나의 출력 분포로 결합하기 위해 soft-gated pointer-generator copying을 사용
(domain, slot)에 대한 value를 예측하기 위해, state generator의 디코더로서 GRU를 사용함
state generator는 J pairs를 독립적으로 디코딩함
decoder의 첫번째 입력으로 domain과 slot의 임베딩값을 더하여 제공
j 번째 (domain, slot) pair에 대한 k 번째 디코딩 스텝에서 generator GRU는 word embedding $W_{jk}$를 입력으로 받고, hidden state $h_{jk}$를 출력으로 내보냄
[state generator 동작 과정]
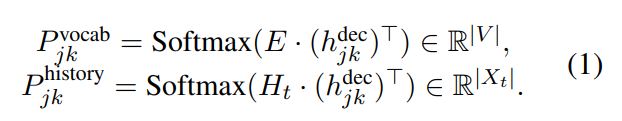
-
hidden state $h_{jk}$를 vocabulary space $P_{jk}$로 맵핑 (학습가능한 파라미터에 의해 맵핑됨)
-
hidden state $h_{jk}$를 인코딩된 dialogue history $H_{t}$에 대한 history attention $P_{jk}$를 계산하기 위해 사용됨
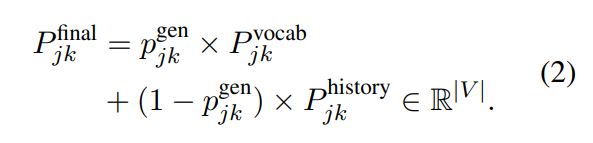
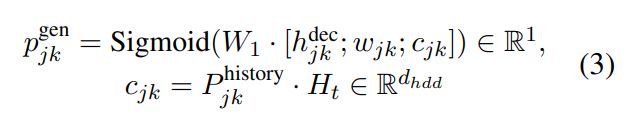
-> 최종적으로 $P_{jk}^{vocab}$, $P_{jk}^{history}$를 두 확률분포를 결합하기 위해 학습을 통해 얻어진 $p_{jk}^{gen}$를 통해 결합
Slot Gate
single-domain DST 문제와 달리, multi-domain DST 문제는 많은 수의 (domain, slot) pairs가 존재하기 때문에 현재 turn t에서 domain과 slot을 예측하는 것이 더 어려움
context-enhanced slot gate G는 인코더의 hidden states $H_{t}$를 ptr, none, doncare 클래스에 대한 확률 분포로 맵핑시키는 단순한 three-way classifier
만약 slot gate의 예측이 none 이나 doncare 이면 디코더에 의해 생성된 value를 무시하고, “not-mentioned” 나 “does not care”로 채움
만약 slot gate의 예측이 ptr 이라면, 디코더에 의해 생성된 value로 채움
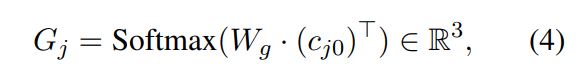
Optimization
학습 시, slot gate와 state generator를 모두 최적화시켜야 함
-
slot gate의 예측값 $G_{j}$와 정답 라벨인 $y_{j}^{gate}$ 사이의 cross-entropy loss
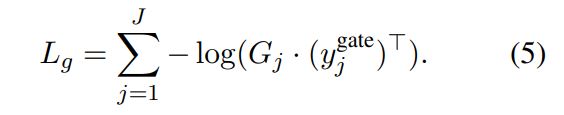
-
state generator의 예측값인 $P_{jk}^{final}$과 정답 단어인 $Y_{j}^{label}$ 사이 cross-entropy loss
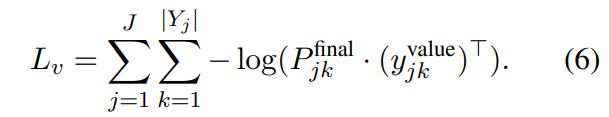
위의 2개의 loss를 가중치를 두고 합하여 최종적인 loss로 사용함
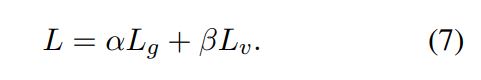
Leave a comment