
[Paper Review] Dense passage retrieval for open-domain question answering
Dense passage retrieval for open-domain question answering
Karpukhin, Vladimir, et al. “Dense passage retrieval for open-domain question answering.” arXiv preprint arXiv:2004.04906 (2020).
Abstract
ODQA(Open-domain question answering)은 passage retrieval 효율에 의존적임
전통적인 sparse vector space models인 TF-IDF, BM25가 주로 사용되었음
논문에서는 dense representations만을 단독으로 이용하여 실용적인 retrieval가 구현될 수 있음을 증명
단순한 dual-encoder framework로 적은 수의 questions, passages로부터 embeddings 학습
다양한 open-domain QA datasets에서 LuceneBM25 system을 9%-19% 정도 뛰어넘는 정확도 달성 (top-20 기준)
다양한 open-domain QA benchmarks에서 end-to-end QA system의 새로운 SOTA
Introduction
ODQA는 큰 documents 모음을 이용하여 질문에 대한 답을 하는 task
초기 QA 시스템들은 복잡하고, 다양한 요소로 구성되어 있었지만, reading comprehension models의 발전으로 간소화된 two-stage framework 제안됨
-
2-stages : retrieval -> reader
-
질문에 대한 답을 포함하는 passages set을 선택하는 context retriever
-
retrieved contexts를 읽고, 올바른 답을 찾는 machine reader
-
이런 프레임워크는 매우 합리적인 방법이지만, 상당한 성능 감소 문제가 있어 retrieval 성능을 향상시켜야 할 필요가 있음
open-domain QA에서 기존 사용하던 retrieval은 TF-IDF 또는 BM25 (sparse retrieval)
keywords가 얼마나 일치하는지 계산하는 방식이고, question과 context를 고차원, sparse vector로 representation 시킴
반면, dense retrieval은 의미적인 인코딩을 하는 방식으로 sparse representation을 보완할 수 있음
-
dense retrieval 방식이 필요한 이유
동의어나 paraphrasing 표현이 서로 비슷한 위치에 맵핑될 수 있게 함
question : “Who is the bad guy in lord of the rings?”
context : “Sala Baker is best known for portraying the villain Sauron in the Lord of the Rings trilogy.”
위와 같은 예시에서 dense retrieval 방식은 bad guy와 villain가 비슷한 단어라는 것을 파악하고, 적절한 context를 선택하겠지만, sparse retrieval 방식에서는 해결하기 어려운 문제임
dense encodings은 embedding 함수들을 조정하여 유연하게 학습 가능함 (task-specific)
in-memory 데이터 구조와 indexing 기술과 함께, MIPS(maximum inner product search) 알고리즘을 이용하여 효율적으로 retrieval 사용 가능
하지만, 좋은 dense vector representation을 학습시키려면 대규모 라벨링 데이터가 필요했기 때문에 ORQA 이전에는 open-domain QA에서 TF-IDF/BM25의 성능을 능가하지 못함
ORQA : pretraining을 위해 마스킹된 문장을 포함하는 블록을 예측하는 정교한 inverse cloze task(ICT) objective 제안
question encoder와 reader model은 questions과 answers 쌍을 사용하여 공동으로 fine-tuning 됨
ORQA는 다양한 open-domain QA datasets에서 새로운 SOTA 달성하고, dense retrieval이 BM25를 능가하는 것을 성공적으로 보여줌
하지만, 여전히 두가지 약점이 존재함
-
ICT pretraining은 계산량이 상당히 크고, 일반적인 문장들이 questions을 잘 대체할 수 있을지 불명확함 (일반적인 문장으로 학습된 모델이 질문에 대해서도 잘동작할 수 있는지)
-
context encoder가 questions, answers 쌍으로 fine-tuning 하지 않는 것은 좋은 representations이 아닐 수 있음 (suboptimal)
본 논문에서는 “추가적인 사전학습 없이 오직 questions과 passages 쌍만을 이용하여 dense embedding model을 더 잘 학습시킬 수 있을지”에 대한 해결책을 찾음
논문은 상대적으로 적은 양의 question, passage 쌍을 이용한 가벼운 학습 방식을 발전시키는데 초점을 맞춤
철저한 ablation studies를 통한 최종적인 솔루션은 question과 relevant passage 벡터간 내적을 최대화시키는 방식으로 최적화되는 매우 간단한 방식
유사한 질문과 지문 사이 내적 최대화, 관련없는 질문과 지문 사이 내적 최소화
Dense Passage Retrieval(DPR)은 BM25를 큰 폭으로 뛰어넘었고 (65.2% vs 42.9% in Top-5 accuracy), open Natural Questions settings에서 ORQA와 비교하였을 때 end-to-end QA 정확도를 상당히 향상시킴 (41.5% vs 33.3%)
Contributions
- 적절한 학습과정으로 존재하는 question-passage 쌍들로 question encoder와 passage encoder를 fine-tuning 하는 방식이 BM25 성능을 상당히 뛰어넘는 것을 보여줌
또한, 경험적으로 추가적인 pretraining이 필요하지 않다는 것을 제시
- open-domain question answering에서 높은 retrieval 정확도가 end-to-end QA 정확도에 중요하다는 것을 확인함
최근 reader model에 DPR을 적용하였을 때, 다양한 QA 데이터셋에서 견줄만하거나 더 높은 성능을 달성함
Dense Passage Retriever (DPR)
open-domain QA에서 retrieval 향상에 집중
M개의 text passages가 주어졌을 때, DPR의 목적은 모든 passages를 저차원 연속 벡터공간에 indexing 하는 것이고, 이를 통해 run-time 시 reader를 위한 관련 passages (top-k)를 효율적으로 찾아줄 수 있음
M은 매우 큰 수(2,100만 passages)이고, k는 일반적으로 작은 수(20-100)
Overview
DPR은 모든 text passage를 d 차원 real-valued vectors로 맵핑시키는 dense encoder \(E_{p}\)를 사용하고, retrieval을 위해 사용할 모든 M passages에 대한 index를 생성
run-time 시, DPR은 입력 question을 d-차원 벡터로 맵핑시켜주는 encoder \(E_{Q}\) 적용하고, 벡터들 중 질문과 가장 가까운 k개의 passages를 찾아냄
question과 passage 간 유사도는 dot product를 이용하여 계산
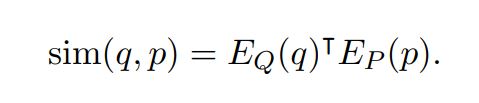
cross attentions의 다양한 layer로 구성된 유사도 계산 모델이 존재하지만, DPR에서는 passages representations을 미리 수행한 후 유사도를 계산하기 때문에 분리가능한 방식을 사용해야 함
Encoder
이론상으로 question, passage encoders는 어떤 모델도 적용 가능함
논문에서는 2개로 독립적인 BERT encoder를 이용하였고(base, uncased), [CLS] token representation 사용 (d=768)
Inference
inference 시, passage encoder \(E_{P}\)를 모든 passages에 적용하고, FAISS를 이용하여 인덱싱
FAISS는 오픈소스 라이브러리로 사용 가능하고 dense vectors 클러스터링으로 유사 벡터를 매우 효율적으로 찾을 수 있도록 함
run-time 시, question q가 주어지면 \(E_{Q}(q)\)로 embedding \(v_{q}\)을 얻고, 이와 가까운 top k개의 passages를 찾아냄
Leave a comment