
[Paper Review] Attention is all you need
Enriching word vectors with subword information
Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems 30 (2017).
Abstract
시퀀스 변환 모델들은 encoder와 decoder를 포함하는 복잡한 순환 신경망이나 컨볼루션 네트워크 기반으로 이루어져 있고, 가장 성능이 뛰어난 모델들은 attention mechanism을 통해 encoder와 decoder를 연결시킨 구조를 사용
논문에서는 순환 신경망과 컨볼루션 없이 오직 attention mechanisms 만을 사용하는 새로운 네트워크 제안 (Transformer)
2개의 기계 번역 task에 대한 실험에서 이 모델은 상당히 좋은 성능을 보였고, 기존 모델들보다 더 병렬화가 가능하고 적은 학습 시간을 필요로 함
WMT 2014 English-to-German translation task에서 28.4 BLEU를 달성하여 기존 최고 성능을 뛰어넘음
8 GPU로 3.5일 동안 학습시킨 후, WMT 2014 English-to-French translation task에서 새로운 단일 모델 SOTA 달성 (41.8 BLEU)
대규모 데이터셋, 제한된 데이터셋 모두에서 Transformer를 영어 구문 분석에 성공적으로 적용시킴으로써 일반적으로 잘동작하는 것을 증명함
Introduction
language modeling, machine translation 과 같은 시퀀스 모델링과 변환 문제에서 RNN(LSTM, GRU)가 SOTA 방식들로 자리잡게 되었고, 이후 반복적인 언어 모델과 encoder-decoder 구조를 발전시키기 위해 다양한 시도가 있었음
Recurrent models은 일반적으로 입력 시퀀스와 출력 시퀀스의 symbol 위치에 따라 계산됨
이전 hidden state \(h_{t-1}, x_{t}\)를 입력으로 받아 현재 hidden state \(h_{t}\) 계산
이전 값을 계산하고 난 후 현재값을 계산하는 순차적 계산 특성 때문에, 학습 데이터 내 병렬화가 불가능하고, 이는 시퀀스 길이가 길어질수록 비효율적임
factorization tricks, conditional computation을 통해 최근 연구에서 계산 효율성을 상당히 높였지만, 여전히 근본적인 문제는 해결되지 않았음
Attention mechanisms은 입력 시퀀스나 출력 시퀀스에서 그들의 거리에 상관없이 모델링하는 것을 가능하게 하여 다양한 task에서 강력한 시퀀스 모델링과 변환 모델의 필수적인 부분
하지만, 이는 대부분 단독으로 사용되지 않고 RNN과 결합하여 사용됨
논문에서는 입력과 출력 간 global dependencies를 끌어내기 위해, recurrence를 이용하지 않고 attention mechanism만에 의존하는 Transformer 모델을 제안
Transformer는 훨씬 더 많은 병렬화가 가능하고, 8개의 P100 GPU에서 12시간 동안 학습한 후 번역 품질 SOTA 성능에 도달함
Model Architecture
가장 경쟁력 있는 neural sequence transduction models은 encoder-decoder 구조를 가짐
encoder : input sequence of symbol representations \((x_{1},...,x_{n})\) -> sequence of continuous representations \(z = (z_{1},...,z_{n})\)
decoder : \(z\) -> output sequence \((y_{1},...,y_{m})\)
모델은 매 time step 다음 시퀀스를 생성하기 위한 입력으로 이전에 생성된 symbols을 받음 (auto-regressive)
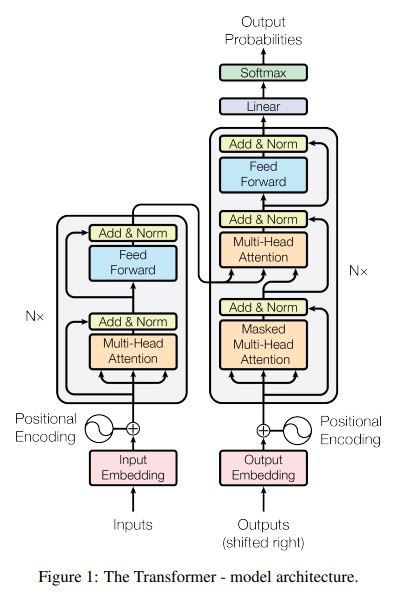
Transformer은 encoder-decoder 모두에 self-attention, point-wise, fully connected layers가 쌓여있는 위 그림과 같은 구조로 이루어짐
Encoder and Decoder Stacks
- Encoder:
6개의 동일한 layer 블럭이 쌓이는 구조 (N=6)
각 layer 블럭은 2개의 sub-layers로 구성됨
multi-head self-attention mechanism + position-wise fully connected feed-forward network
각 sub-layer에서 layer normalization 전에 residual connection 적용시킴 (\(LayerNorm(x + Sublayer(x))\))
residual connection을 사용하기 위해 모든 차원을 통일함 (\(d_{model} = 512\))
- Decoder:
6개의 동일한 layer 블럭이 쌓이는 구조 (N=6)
encoder layer 블럭과 다르게, encoder output에 대한 multi-head attention을 수행하는 새로운 sub_layer가 삽입됨
encoder과 동일한 방식으로 residual connection을 적용
이후 단어를 미리 보는 것을 방지하기 위해 self-attention sub_layer 수정
output embeddings에 대한 위치 정보만 1로 masking
Attention
attention function은 output에 대한 하나의 query와 key-value 쌍들 중 하나를 맵핑시킴
query, keys, values 모두 벡터
출력은 values의 weighted sum으로 계산되면, 여기서 각 value에 할당된 가중치는 해당 key와 query의 호환성 함수(Softmax 값)에 의해 계산됨
Scaled Dot-Product Attention
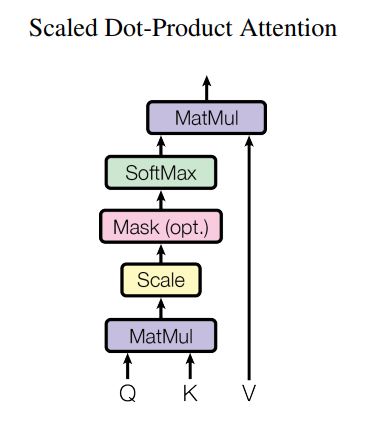
input : \(d_{k} dimension\)을 가진 queries와 keys, \(d_{v} dimension\)을 가진 values
하나의 query에 대해 모든 keys와 dot products를 계산한 후, values에 대한 weights를 얻기 위해 \(\sqrt{d_{k}}\)로 나누고 softmax 적용
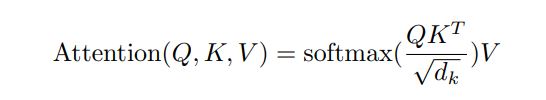
Q : query, K : keys, V : values
모든 query를 matrix Q로 묶어서 연산 수행
attention에서 가장 많이 사용되는 방식은 additive attention과 dot-product attention 이고, 논문은 dot-product에 scaling factor \(\sqrt{d_{k}}\)를 추가한 방식 사용
\(d_{k}\) 값이 커지면, dot product 결과값도 너무 많이 커지면서 softmax 함수를 통과시켰을때, 적절한 예측을 수행하기 어렵기 때문에 scaling factor를 사용
두가지 방식의 이론상 계산 복잡도는 유사하지만, dot-product attention은 행렬 곱으로 연산을 구성할 수 있어서 훨씬 빠르고 효율적인 연산이 가능함
Multi-Head Attention
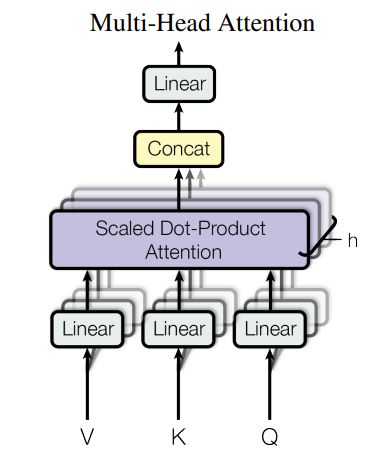
single attention 방식보다 h 번 다르게 학습된 queries, keys, values 값을 projection하는 것(mulit-attention)이 더 좋은 성능을 보이는 것을 발견함 (h=8)
병렬적으로 attention을 각각 수행하고, concat을 통해 최종 결과값을 얻어냄

\(d_{k} = d_{v} = d_{model}/h = 64\)로 설정하여 single-head attention과 유사한 연산량을 갖도록 함
Applications of Attention in our Model
3가지 방식의 mulit-head attention 사용
- encoder-decoder attention
이전 decoder layer에서 나온 queries와 encoder의 출력으로 나온 keys와 values 값을 이용
decoder의 모든 위치에서 input sequence의 모든 위치에 대한 정보를 얻을 수 있게 함
seq2seq 모델의 일반적인 encoder-decoder attention 모방
- self-attention layers in encoder
이전 encoder의 출력값에서 query, key, value 값을 입력을 받아서 attention 수행
현재 encoder의 각 위치에서 이전 encoder의 모든 위치에서 정보를 얻을 수 있음
- self-attention layers in decoder
decoder 각 위치에서 현재 위치까지의 정보를 얻을 수 있음 (현재 위치 다음 단어를 미리 볼 수 없게 제한)
masking out을 통해 보지 말아야 할 위치의 모든 값들을 \(-\infty\)으로 설정
Position-wise Feed-Forward Networks
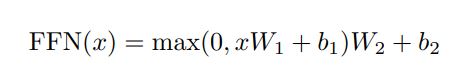
2번의 선형변환과 1번의 ReLU를 사용
kernel size가 1인 convolution을 2번 진행하는 방식과 동일 (512 -> 2048 -> 512)
Leave a comment