
[Paper Review] A strong baseline and batch normalization neck for deep person re-identification
A strong baseline and batch normalization neck for deep person re-identification
Luo, Hao, et al. “A strong baseline and batch normalization neck for deep person re-identification.” IEEE Transactions on Multimedia (2019).
Abstract
- 단순하지만 강력한 deep person re-identification(ReID) baseline 제안
기존의 SOTA 방식들은 복잡한 네트워크 구조이며 multi-branch features를 concatenation 시킴
- person ReID를 위한 효과적인 training tricks을 수집하고 평가함
이런 tricks을 결합하여 MarKet1501에서 ResNet50의 global features만을 사용하여 높은 성능을 냄
기존 global-based 방식들과 part-based 방식들의 성능을 능가함
- BNNeck : batch normalization neck이라는 이름의 새로운 neck 구조를 제안
metric loss와 classification loss를 2개의 다른 feature space로 분리시키기 위해, global pooling layer 후에 batch normalization layer를 추가함
하나의 embedding space에서는 일관적이지 못한 결과를 보이기 때문에 분리를 시키는 것
-
실험을 통해 BNNeck이 baseline의 성능을 향상시키는 것을 보여주었고, 우리의 baseline은 기존 SOTA 방식들을 성능을 향상시킬 수 있음
-
code : https://github.com/michuanhaohao/reid-strong-baseline
Introduction
-
효과적인 training tricks을 수집하고 평가하면서 person ReID를 위한 강력하고 효과적인 baseline을 디자인함
-
논문의 3가지 motivation
1) 2018년도 ECCV와 CVPR 논문들을 조사
총 23개의 baseline이 있고, 이 중에서 rank-1 accuracy가 90%을 넘는 baseline은 2가지만 존재함
강력한 baseline을 제공하기 위해 기존의 연구들은 분석

2) 여러 연구들에서 성능 향상의 요인이 모델 자체보다는 training tricks에 존재하는 것을 발견
연구들은 다른 SOTA들과 불공정하게 비교를 하였음
training tricks에 대해 축소하여 언급하면서 모델의 효과를 과장되게 표현함
reviewers가 이런 tricks을 고려할 수 있도록
3) 산업에서는 간단하지만 효과적인 모델을 선호
기존에 성능 향상을 위해 pose estimation 또는 segmentation models에서의 정보를 결합시키는 방식들이 있으나, 이는 추가적인 계산비용이 들어가기 때문에 속도가 빠르지 못함
우리는 추가적인 계산비용 없이 오직 모델에서 추출된 global features만을 활용하고, tricks을 사용하여 ReID model의 capability를 향상시킴
- 기존의 연구들을 분석하여 총 6개의 tricks을 소개하고, 새로운 bottleneck(BNNeck) 구조를 제안
classification loss와 metric loss는 같은 embedding space에 일관성 없는 결과를 보이기 때문에, BNNeck은 2개의 losses를 다른 2개의 embedding space에서 최적화 시킴
- person ReID task는 ranking performance(cumulative match characteristic,mAP)에 초점을 맞추고, clustering effect(intra-class compactness, inter-class separability)는 무시함
하지만, clustering effect도 object tracking과 같은 특정 tasks에서는 중요함
이를 해결하기 위해 center loss를 이용하여 모델을 학습 시킴
- 마지막으로, 우리의 수정된 baseline을 얻기 위해 기존의 baseline에 tricks을 추가 (backbone : ResNet50)
- 이러한 tricks이 일반적으로 유용한지 아닌지를 결정하기 위해, 3가지 관점에서 실험을 진행
1) the cross-domain ReID settings
모델을 training 시키고, 다른 datasets에서 평가
tricks이 모델의 성능을 향상시키는 것인지 단순히 학습 dataset에서 overfitting을 억제하는 것인지 실험을 통해 확인
2) 여러 backbones에서 모든 tricks을 평가
3) SOTA 방식들을 우리의 baseline으로 재구성
Contributions
-
효과적인 training tricks을 수집하고, 이들을 2개의 datasets에서 평가
-
ID loss와 triplet loss 사이 inconsistency를 발견하고, 새로운 neck 구조(BNNeck) 제안
-
ReID task는 intra-class compactness와 inter-class sepability를 무시하는 것을 발견하고, 이를 해결하기 위해 center loss 사용을 주장
-
강력한 ReID baseline 제안
-
실험을 통해 우리의 baseline이 강력하다는 것을 증명
Our strong baseline and training tricks
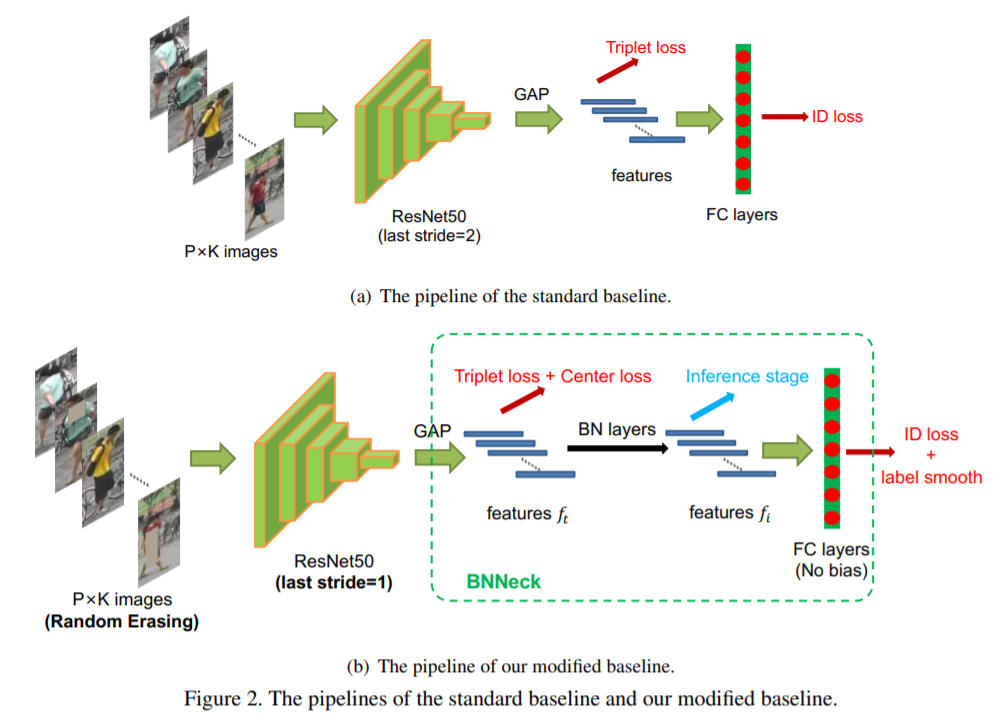
A. Warmup learning rate
- learning rate는 ReID 모델 성능에 큰 영향을 끼침

B. Random erasing augmentation
- person ReID에서 이미지 속 사람들은 종종 다른 objects에 의해 가려져 있음
occlusion 문제를 해결하고 ReID 모델의 capability를 향상시키기 위해, data augmentation을 사용
- random erasing augmentation(REA) : 랜덤으로 training image에 사각형의 masks가 생성됨 (probability p 설정)
C. Label Smoothing
- person ReID에서 basic baseline는 IDE 네트워크
마지막 layer에서 이미지들의 ID perdiction logits(p_i) 출력
- The ID loss

- training IDs에 오버피팅되는 것을 방지하기 위해 Label smoothing(LS) 방식 사용

D. Last Stride : last spatial down-sampling operation
-
high spatial resolution은 features를 풍부하게 함
-
last stride를 제거하면 feature map 사이즈가 2배로 커지며, 이는 상당한 성능 향상을 가져옴
computation costs는 살짝 증가하지만, 추가적인 training 파라미터는 필요하지 않음
E. BNNeck
- fig4(a)와 같이, 많은 SOTA 방식들이 ID loss와 triplet loss를 결합하여 사용함
이는 모델이 좋은 성능을 내도록 하지만, embedding space에서 inconsistency의 원인이 됨
- ID loss는 embedding space를 다른 subspaces로 분리하기 위해, 여러 개의 hyperplanes을 생성
ID loss를 최적화시킬 때, Euclidean distance 보다 cosine distance가 더 적합함

- triplet loss는 Euclidean distance에 의해 계산되고, Euclidean space에서 intra-class compactness, inter-class separability를 향상시킴
cluster distribution

- 이 두개의 loss를 한 feature space에서 최적화 시키면, 일관적이지 못한 결과가 나옴
각 loss의 값이 커지고 작아지고를 반복

- BN layer를 추가하여 embedding space에서의 feature 분포를 부드럽게 만들어 줌



- BNNeck

intra-calss compactness를 향상시킬 수 있음
- 최종 features에 BN layer를 적용

F. Center loss
- person ReID는 ranking 결과에 의해 평가되고, clustering 효과는 무시됨
하지만 tracking task와 같은 applications에서는 clustering effect가 중요함

- 기존의 문제를 해결하기 위해 center loss를 포함하여 학습을 진행

각 클래스의 deep features에 대한 센터를 학습하며, deep features와 그에 상응하는 클래스 센터 사이의 거리를 penalizing
- the total loss

Leave a comment