
[Paper Review] Fast r-cnn
Fast r-cnn
Girshick, Ross. “Fast r-cnn.” Proceedings of the IEEE international conference on computer vision. 2015.
Abstract
-
deep convoluional networks를 사용하여 효율적으로 object proposals을 분류
-
기존의 방식들보다 정확하고, training과 testing 속도가 빠름
R-CNN과 비교하였을 때, training time에 R-CNN보다 9배 빠르고, testing time에는 213배 빠름
SPPnet과 비교하였을 때, training time에 3배 빠르고, testing time에 10배 빠름
Introduction
- 기존 object detection 방식들은 multi-stage 방식으로 training을 진행하였는데, 이런 방식들은 2가지 challenge가 존재함
-
무수히 많은 proposals이 처리되어야 함
-
이때, candidates의 localization 결과는 정밀하지 않음
- 본 논문은 이런 과정을 간소화시켜, classification과 bounding box regression을 공동으로 학습하는 single-stage training 알고리즘을 제안함
PASCAL VOC 2012에서 제일 높은 정확도를 냄
R-CNN and SPPnet
- R-CNN의 3가지 결점
- 학습 과정이 multi-stage 방식임
log loss를 사용하여 proposals을 통해 ConvNet을 finetuning하고, SVMs을 ConvNet features에 맞추고 이것이 detectors로 동작함
다음 stage로 bounding-box regressors가 학습됨
- 학습과정에서 메모리와 시간 소모가 큼
SVM과 bounding-box regressor를 학습시키기 위해, 하나의 이미지에서 추출된 모든 proposals로부터 features를 추출하고 이를 disk에 저장해야 함
- detection 속도가 느림
한 장의 이미지에 대한 testing time이 약 47초
-
SPPnet은 R-CNN과 다르게 전체 이미지에서 하나의 features를 추출하고, 공유된 feature map에서 feature vector를 추출하여 proposal로 분류하면서 속도를 상당히 가속화 시킴
-
SPPnet의 결점
-
R-CNN과 마찬가지로 multi-stage 방식으로 학습을 진행
-
convolutional layers를 update 할 수 없음 (고정된 convolutional layers로 정확도에 제한이 생김)
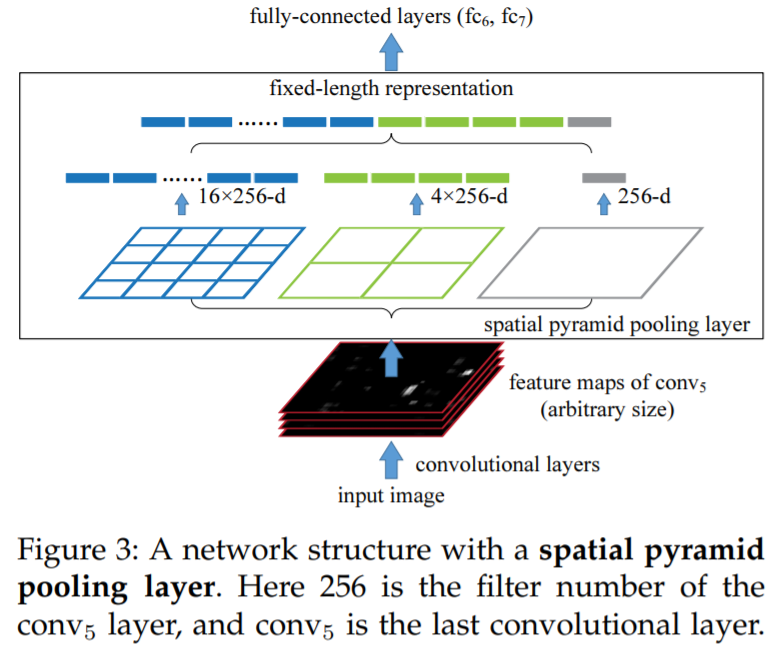
- Contributions
-
R-CNN, SPPnet보다 mAP가 높음
-
multi-task loss를 사용한 single-stage 방식의 학습과정
-
feature caching을 위한 disk 공간이 필요하지 않음
Fast R-CNN architecture and training
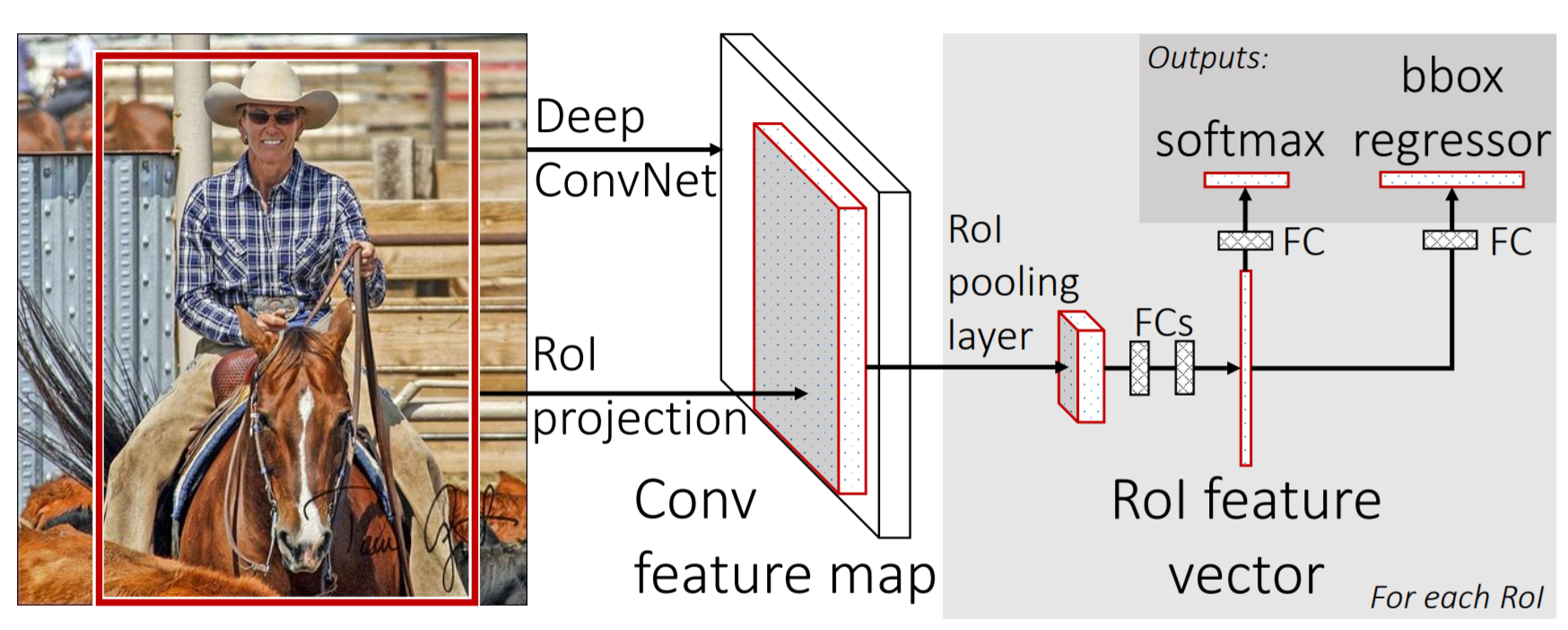
input : 전체 이미지, object proposals의 집합
-
feature map을 생성하기 위해 전체 이미지를 네트워크의 입력을 넣음
-
추출된 feature map에서 object proposal에 대하여 RoI projection을 수행 (feature map에서 proposals 생성)
-
RoI pooling layer를 통해 고정된 길이의 feature vector를 얻음
-
feature vector를 fc layers에 넣고, 이를 2개의 branch로 나누어 classification과 bounding box regression 수행
The RoI pooling layer
-
다양한 크기의 features를 고정된 사이즈의 feature vector로 맞춰주는 과정이 필요함
-
RoI 내 features를 고정된 사이즈의 작은 feature map으로 변환시키기 위해 max pooling을 사용하고, 이후 fc layer를 통해 feature vector로 mapping 시킴
기존 features 사이즈인 h x w를 고정된 H x W 사이즈로 맞추기 위해, pooling section을 나누어 max pooling 수행 (h/H x w/W)
Initializing from pre-trained networks
- 3개의 pre-trained ImageNet networks를 통해 실험함
이를 Fast R-CNN에 적용시키기 위해서 3가지 변형이 필요
-
마지막 max pooling layer를 RoI pooling layer로 변경
-
네트워크의 마지막 fc layer와 softmax를 2개의 sibling layers로 변경
-
네트워크가 2개의 input을 받을 수 있도록 변경 (image list, RoIs list)
Fine-tuning for detection
- Multi-task loss
- multi-task loss L : classification + bounding-box regression
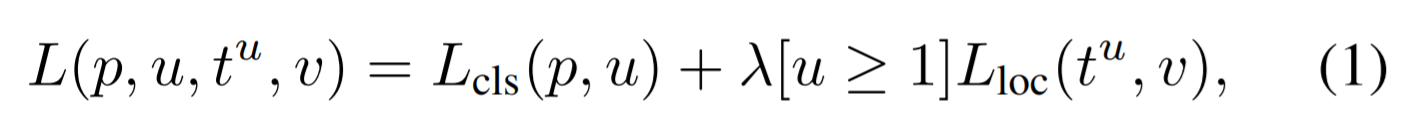
-
Multi-batch sampling
-
Back-projection through RoI pooling layers
-
SGD hyper-parameters
Scale invariance
-
brute force learning : training과 testing time에 미리 정의된 pixel size로 이미지 처리
-
using image pyramids : data augmentation 형태로 이미지가 샘플링 될 때마다 피라미드 scale을 무작위로 샘플링
Leave a comment