
[Paper Review] Improving language understanding by generative pre-training
Improving language understanding by generative pre-training
Radford, Alec, et al. “Improving language understanding by generative pre-training.” (2018).
Abstract
자연어 이해는 textual entailment, question answering, semantic similarity assessment, document classification 등과 같이 광범위한 task들로 구성되어 있음
라벨링 되지 않은 대규모 데이터는 많이 있지만, 특정 tasks를 학습하기 위한 라벨링 데이터는 부족
이는 task에 맞춰 학습되는 모델들이 적절한 예측을 수행하는 것을 어렵게 만듦
논문에서는 다양한 라벨링 되지 않은 텍스트 데이터에서 언어 모델의 pre-training(generative pre-training)을 통해 이러한 task에서 좋은 성과를 냄
특정 task에 적용시킬 때는 fine-tuning 수행 (discriminative fine-tuning)
기존 접근법들과 달리, 모델 구조 변경을 최소화하면서 효과적인 transfer를 하기 위해 task에 따라 입력을 변형하여 fine-tuning 함
다양한 자연어 이해 benchmarks에서 논문의 접근법이 효과적이라는 것을 증명함
논문에서 제안한 task에 관계없이 사용가능한 모델(task-agnostic)은 특정 task를 위한 구조로 차별적으로 학습된 모델들을 뛰어넘음 (12개 task 중에 9개에서 SOTA 달성)
특히, commonsense reasoning에서 8.9%, question answering에서 5.7%, textual entailment에서 1.5% 향상을 보임
Introduction
자연어처리에서 지도학습에 대한 의존성을 완화시키기 위해, raw text(unlabeled text)에서 효과적으로 학습하는 능력은 매우 중요함
하지만, 대부분의 딥러닝 방식들은 상당한 양의 labeled data를 필요로 하고, 이는 labeling 된 데이터가 부족한 많은 분야에서 이러한 방식들이 사용되는 것을 제한함
- GPT-1 과 같은 모델이 필요한 이유
1) 라벨링 되지 않은 데이터로부터 언어 정보를 이용할 수 있는 모델은 많은 annotation을 얻어야만 이용할 수 있던 기존 방식의 귀중한 대안책이 될 수 있음
또한, 데이터를 라벨링 하는 것은 시간이 오래 걸리고 많은 비용이 듦
2) 비지도 방식으로 좋은 representation을 학습하는 것은 상당한 성능 향상을 불러옴
대표적인 예시, pre-trained word embeddings의 사용으로 다양한 NLP tasks에서 성능 향상이 있었음
- unlabeled text에서 word-level 정보 이상을 얻어내는 것이 어려운 이유
1) transfer에 유용한 text representaions을 학습하는 데 어떤 optimization objectives가 좋은 명확하지 않음
2) 학습된 representations을 target task로 전이시키는 효과적인 방법이 무엇인지에 대한 합의점이 없음
기존 방식들은 특정 task를 위해 모델의 구조를 변경시키는 방식으로 적용함
논문에서는 unsupervised pre-training과 supervised fine-tuning을 결합한 semi-supervised 방식을 제안함
다양한 자연어처리 tasks에 적은 변경만으로 전이시킬 수 있는 보편적인 representation을 학습시키는 것이 논문의 목표
- two-stage training procedure
1) neural network model의 초기 파라미터를 학습시키기 위해, unlabeled data에 하나의 언어 모델링 objective 사용
2) 학습시킨 파라미터들을 target task에 적용시키기 위해, task에 맞는 supervised objective 사용
Framework
-
대규모 텍스트 데이터에서 수용력 있는 언어 모델 학습
-
labeled data와 함께 특정 task에 모델 적용
Unsupervised pre-training
unsupervised corpus of tokens \(u = {u_{1},...,u_{n}}\)가 주어지면, 아래 수식과 같은 대표적인 언어 모델링 objective 사용하며 SGD를 이용하여 최적화시킴
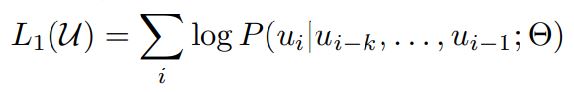
k : context window size / P : conditional probability
언어 모델에 하나의 multi-layer Transformer decoder를 사용하고, input context tokens에 대해 multi-headed self-attention 연산을 적용시킴
attention 이후, output 확률값을 구하기 위해 position-wise feedforward layers로 들어감
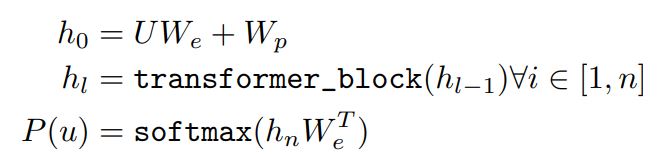
\(U = (u_{-k},...,u_{-1})\) : context vector fo tokens / n : layers의 수 / \(W_{e}\) : the token embedding matrix / \(W_{p}\) : position embedding matrix
Supervisied fine-tuning
pre-training 과정을 거친 후, 파라미터들을 supervised target task로 적용
input tokens의 sequence와 그에 맞는 label y로 구성된 데이터인 labeled dataset C 사용
입력들이 최종적인 transformer block의 activation \(h_{l}^m\)를 얻기 위해 pre-trained model를 통과한 후, task를 수행하기 위한 추가적인 linear layer로 들어감
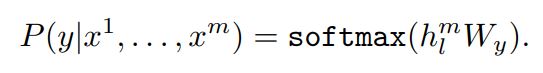
y를 예측하기 위한 파라미터 \(W_{y}\) 학습
- objective
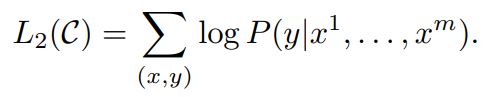
- 언어 모델링을 fine-tuning의 목적함수의 보조로 활용하면, 학습된 모델의 일반성을 향상시킬 수 있고, 수렴을 가속화 시킬 수 있다는 장점이 있음
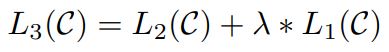
결과적으로, fine-tuning을 위해 필요한 추가적인 파라미터는 \(W_{y}\)와 delimiter에 대한 임베딩 토큰밖에 없음
Task-specific input transformations
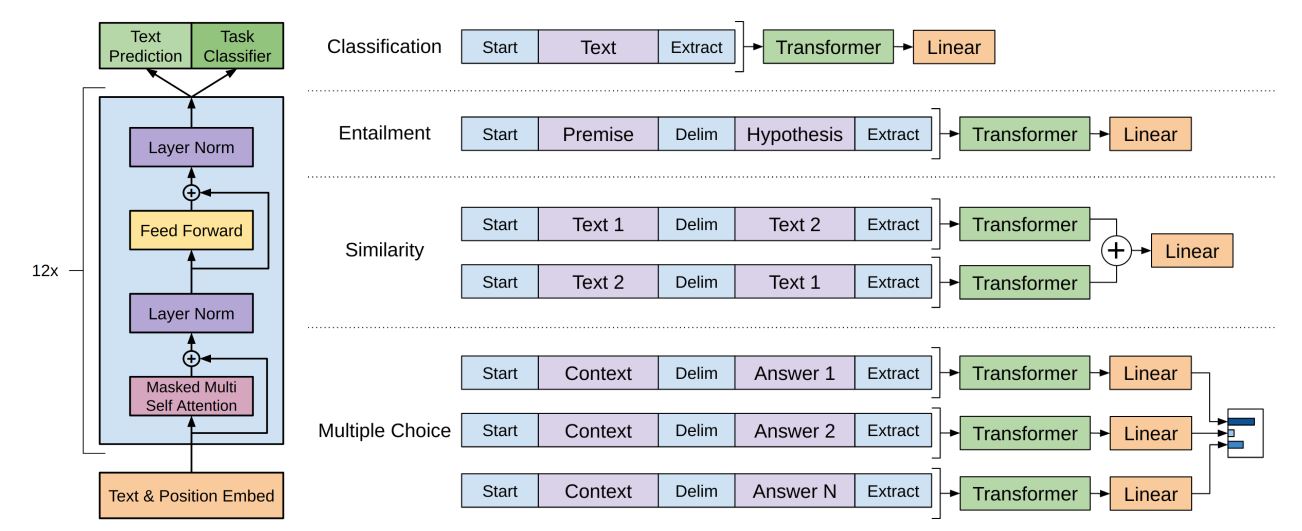
text classification과 같은 특정 tasks를 위해, 위에 그림과 같은 모델을 직접 fine-tuning 해야 함
question answering 이나 textual entailment와 같은 다른 특정 tasks는 순서가 있는 문장 쌍 또는 triplets of document, question, answer과 같이 특정 구조의 input 필요로 함
기존 연구는 transferred representations 위에 특정 task를 위한 구조를 학습시키는 방식을 제안했고, 이런 방식은 특정 task를 위한 상당한 customization이 필요하고 추가적인 구성요소에 pre-training weight를 사용할 수 없다는 단점이 있었음
논문에서는 traversal-style 접근법을 이용하여 구조화된 입력들을 순서가 있는 sequence로 변환하여 pre-trained model이 처리할 수 있도록 함
이러한 입력 변환은 특정 task에 적용할 때 구조의 큰 변화를 피할 수 있게 함
모든 변환들은 랜덤으로 초기화된 start, end tokens
,을 포함
- Textual entailment
premise p와 hypothesis h의 token sequences를 concat시켜 입력으로 사용 (p와 h 사이에 $ 넣고 concatenate)
- Similarity
비교할 두 문장 사이 순서 개념이 모호하기 때문에, A+B, B+A 순서로 붙인 문장을 입력으로 사용하여 각각의 sequence representation \(h_{l}^m\)을 linear layer에 들어가기 전 concat 수행
- Question Answering and Commonsense Reasoning
context document z, question q, 가능한 정답들인 \({a_{k}}\)가 주어지고, document context와 question에 맞는 각각의 answer을 $를 사이에 붙여 concat 시킴
각 시퀀스 쌍은 독립적으로 모델로 처리되고, 가능한 정답에 대한 output 확률값을 구하기 위해 softmax layer를 통해 normalization 됨
Leave a comment